The Delegate Design Pattern is a light weight pattern used to mainly compose behaviours at run time. The Delegate Pattern is used to separate out the concerns by having two objects participate in servicing a request — the object that receives the request and its delegate that does the actual work. Like the Delegate pattern, we can use inheritance in Object Oriented programming languages to pass off work to another object (superclass), but as we shall see, the Delegate Pattern is structurally different to inheritance and brings with it its own strengths and weaknesses.
The Delegate Pattern is quite common and used in almost all software systems, directly or indirectly. Some examples include:
- Consider a network application. When we want to make a network request, we construct the request and delegate it to the object responsible. This delegate will take care of various network configurations, the type of request, how errors are handled etc. The main application will only be concerned with the result of the request and handle errors if any
- Most graphical software use this pattern. The core drawing library will be requested to draw objects for the main application and take care of talking to the OS’s graphics API
- Similarly, a database delegate is used to route requests to query and manipulate data, and not be concerned about the various factors involved in making such a request work
When Should This Pattern Be Used? #
The Delegate Pattern makes it easy to abstract away the complexities involved in performing some work. This pattern can be used to maintain a boundary, about what work is done and by whom. You can use it to decouple the actors in your system and communicate by message passing. This pattern can also help when you need to change behaviour dynamically during runtime. This is simple as pointing to another object using the Delegate Pattern. Also, code re-use is a by product when you use this pattern. If you want to re-use, even when the classes does not exhibit Is-A relationship, delegation is the way to go.
Class Structure And Participants #
A class hierarchy of the Delegate Pattern can have a structure similar to the one shown below.
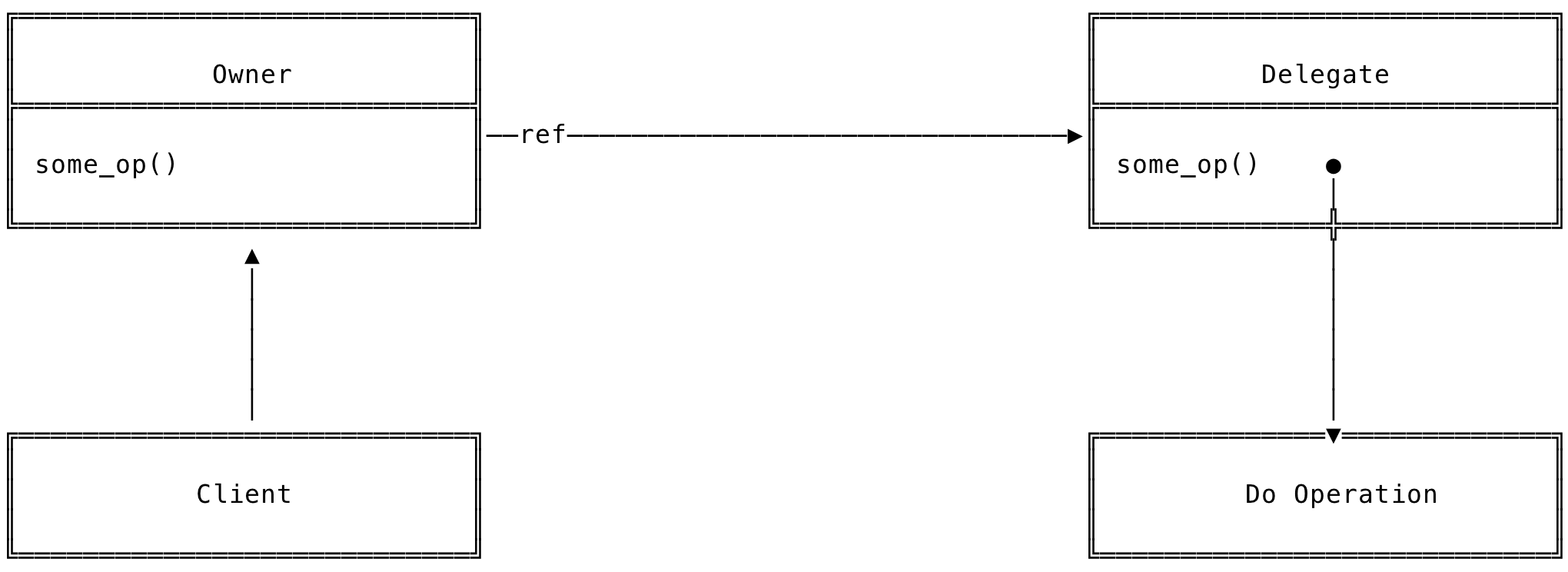
Fig 1: Class Structure - Delegate Design Pattern
Let us take a look at the participants in this design pattern.
Owner: This is the owning class. This will contain a reference to the delegate. When a request comes in, it will be forwarded to the delegate object.
Delegate: This class will do the actual work for the client. This class is responsible for returning the result to the owning object.
Client: Client code that interacts with the classes used in this pattern.
Example Of This Pattern #
We shall now look at an example of this pattern for a better understanding. Below is a class that represents some text data, that it holds in memory.
Now, lets say, we want to spell check the text against a dictionary. This brings a new class to the design — a spell checker. A spell checker can be represented as:
The SpellChecker maintains a set of valid words, pre-built, that it checks against. For simplicity, lets say that the spell_check() method returns the misspelled words in a std::vector<std::string>. In our application we need to get TextData and SpellChecker working together.
When you think about it, the roles and responsibilities of both the objects are different. Logically, the document is different from that of the spell checker and the structure, is kind of, extending the functionality of the other.
In our example, the TextData and SpellChecker can naturally be modelled in a containment relationship. The TextData contains/has-a SpellChecker. This type of relationship is common in Object Oriented Programming and is known as Object Composition.
The TextData class would now look like:
The TextData uses a SpellChecker object to perform the spell check. The client will message a TextData object to perform a spell check on the data and the TextData object will delegate the request to the SpellCheck object that it maintains as part of its state. The SpellCheck object is the one that actually does the spell check and returns back the result to the TextData object. The TextData object is the owner and the SpellCheck object is its delegate.
Now, when a request comes in to TextData to spell check, we just need to forward the request to the delegate. This is as,
void TextData::spell_check()
{
_spell_checker->spell_check(this->get_data());
}
Delegation makes it easy to change behaviour at run-time, based on the task at hand. For example, imagine TextData contains data from an internet chat room and you need to spell check on it. Lets say that the SpellChecker is limited on a check on modern internet lingo. However, you have an AdvancedSpellChecker just for the job. And, AdvancedSpellChecker is defined as follows,
Since, AdvancedSpellChecker derives from SpellChecker and conforms to the same interface, you can change the spell checker to point to the right spell checker before calling spell_check() method on it. This can be done as,
the Delegate Pattern usually involves object composition to structure itself. Let us look at another example. Let us say you need to store the TextData to disk and you need someone to take care of persisting the data. You can introduce the following classes to take care of it,
And the way to use it is,
And this way, you go about building large software applications — out of small well defined objects, by exposing only their public interfaces to get the work done. This pattern helps encapsulate each other and makes them flexible to individual changes without affecting each other. You just need to know about the delegate’s public interfaces to use them.
Benefits Of This Pattern #
- Encapsulation, re-use and flexibility are the main advantages of the Delegate Pattern. Each class in the pattern hides its implementation from each other and separation of concerns happen naturally. This style of re-use is a black-box reuse, because you do not need to know the internals of the other objects present. You can compose large applications out of smaller, well defined ones and can dynamically change the behaviour depending on the context. This provides us with multiple execution strategies using the same set of objects
- Sometimes in your application, the place where the request has originated might not be the best option to handle the request. You might use a specialised object, best suited to handle the request. For example, a UI application might catch a button click event, but such an event might be outside its boundary use-case wise. So instead, it is passed on to a delegate, which work on such events
- When using the Delegate Pattern, you do not need to re-build the owner when one of the delegate changes. The change in delegates can be independent of the owning object, since all that the state the owner maintains - is a pointer to the delegate
Implementation Notes #
- With the Delegate Pattern, the application becomes very dynamic and this makes it hard to reason about its run-time workings. It is easier to hunt down a bug when the structure is static and you have the compiler assisting you
- You need to determine the lifetime and the ownership of the delegates. It does not necessarily be tied to the owning object and if so you need to take care in using it along with others in your application. Ownership is again dependent on your use-case and needs
- Sometimes the delegate might need a reference to the owning object. This can be implemented by the owner passing a reference to itself when calling the delegate
That’s it.
For any discussion, tweet here.
You can download the C++ project, that contains various design patterns featured in this blog, here.