Linux implements an in-memory cache to speedup disk I/O operations. The cache contains most frequently accessed data by processes running in the system. The kernel reserves space for such cache in main memory, manages read/write on it. An access to disk is considerably slower than an access to main memory — milliseconds vs nanoseconds and without the cache, each access to data on the disk will result in slower I/O thereby increasing the latency of the running processes. Data read/written by the processes are managed by the kernel and also takes care of servicing subsequent reads/writes from the cache. And, if the cache has been modified, the kernel manages the write back based on the policies defined.
The OS treats the Page as the basic unit of memory management. A page is typically 4K/8K in bytes. Although the processor’s smallest addressable unit is a word, the Memory Management Unit(MMU) — the hardware that manages memory and performs virtual to physical address translations, along with the kernel deals with pages. More details about how the kernel manages a process in memory can be found here.
The kernel does a read-ahead of pages to further increase the performance of disk I/O operations, on certain valid assumptions. First, data once accessed will, in high likelihood, be accessed again. This property is called temporal locality and when a page is cached during its first access, future read/write to the page is significantly faster due to it already being in the page cache. Next, when a piece of data is bought into the cache, ’nearby’ data will also be accessed in high likelihood. This property is called spatial locality and when a page is bought into the page cache, nearby pages are also bought into the cache in the assumption that an access to those pages are not far off.
The high level workings of such a system will be something like the below:
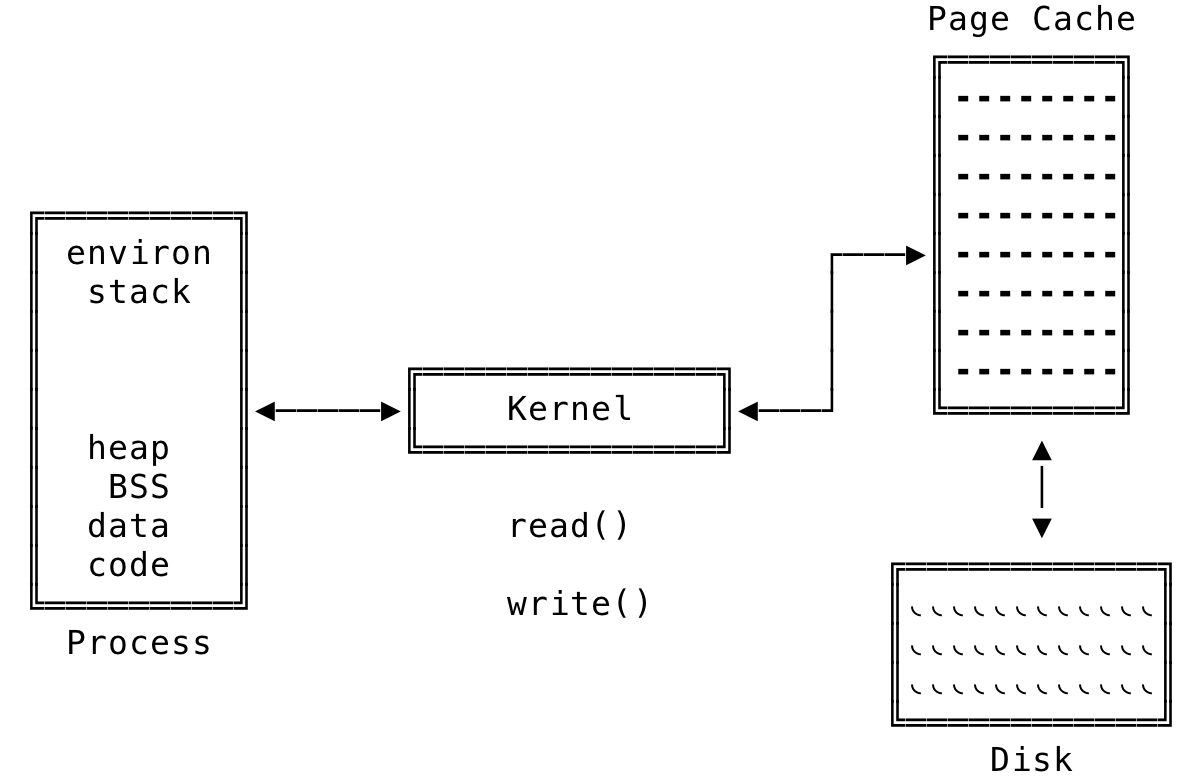
Fig 1: Page Cache at a High Level
The page cache sits in-between the disk and tries to service requests — if possible, before accessing the disk. The page cache is made invisible by the kernel, as in, the processes think they are reading/writing directly to disk. We shall now look at the various operations in more detail and see how the various components tie together to read/write data.
Importantly, the pages in the page cache can originate from reads and writes of regular filesystem files, block device files and memory-mapped files.
Read Caching #
Consider the following request made to the kernel:
n = read(fd, buf, 1024);
Here, we are trying to read 1024 bytes from a disk backed file. As explained above, the MMU and the kernel deals with pages and assuming a X86-32 system with a page size of 4K, the following work is performed by the kernel:
The in-memory page cache is searched to see if the page that contains the requested data is already present. If the page is present, which is a cache hit, the requested data is transferred to the user-space buffer and the process continues execution. Note, the offset from which the data is read depends on the state maintained on the file descriptor (fd), by the kernel data structure.
If the data is not present in the page cache, which is a cache miss, a new page data structure is got over from the slab allocator and placed into the in-memory page cache. The disk is searched and the data corresponding to the offset is copied over into the newly created page. The kernel then copies over the requested data into the user space buffer and the process continues execution.
The read can be visualized as:
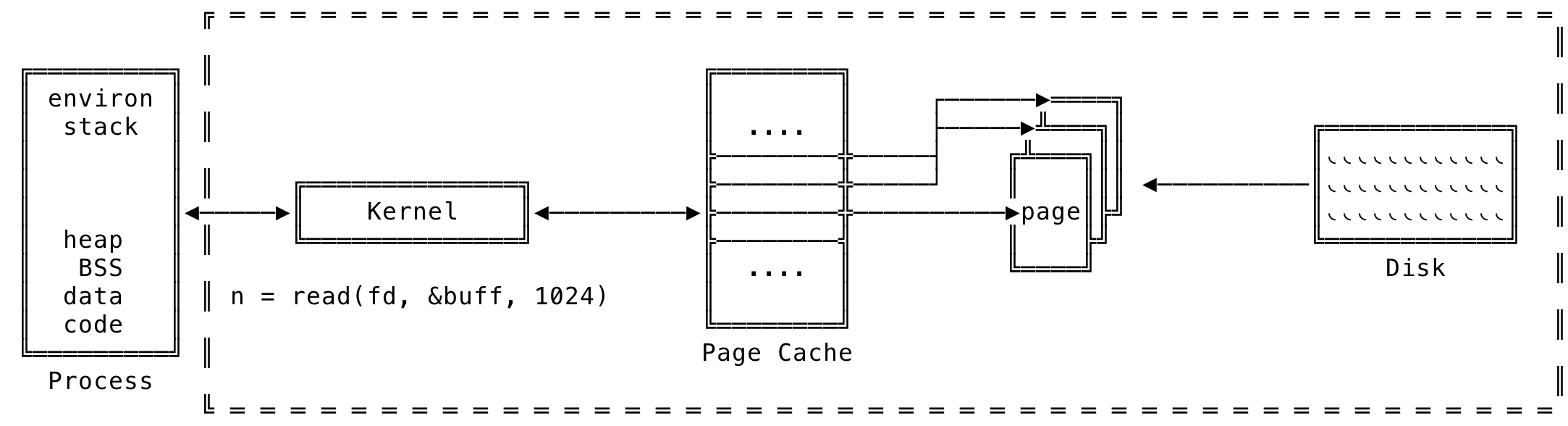
Fig 2: Role of Page Cache during read()
Here, even though we request only 1024 bytes from a specific disk file, the whole page(4K) of data is bought into memory and based on policies defined, other pages are also bought into the page cache at a time. This kernel functionality gives the illusion that a read is instantaneous — when it is the OS doing most of the work to aid the processes.
The following example shows the cache increasing after reading a file. You can check out the amount of memory, used by the cache, using the free command.
vagrant@ubuntu-bionic:~$ free
total used free shared buff/cache available
Mem: 1008948 80480 747800 604 180668 787940
Swap: 0 0 0
vagrant@ubuntu-bionic:~$ vim ~/tmp/random_lines.out
vagrant@ubuntu-bionic:~$ free
total used free shared buff/cache available
Mem: 1008948 80432 741532 604 186984 787840
Swap: 0 0 0
Write Caching #
Now, consider the following request made to the kernel:
n = write(fd, buffer, 1024);
Here, we are trying to write 1024 bytes to a disk backed file descriptor. During a write(), the kernel’s work is two fold. One, it first writes to the in-memory page cache and next, it needs to write the page back to the backing file. The time when the backing file update is done — is dependent on the write-back policy defined. Most implementations use either of the three below policies.
- No Write: Using this policy, the write would be directly written to disk — invalidating the cache. And when a new read comes in, a disk access is made to get the latest value of the data
- Write Through: Using this policy, the write goes through the cache along with the disk. This policy keeps the cache coherent with the disk copy
- Write Back: Most implementations use this approach. Using this policy, the operations are carried out on the cache. The disk copy is not updated immediately. The in-memory page is marked as dirty and are added to the dirty list. A background thread, that runs periodically, is responsible for writing the modified page back to the disk. After the page is successfully written to the disk, the page is removed from the dirty list and is marked as not dirty. And if in-between a read request comes in, they are serviced through the page cache.
The write can be visualized as:
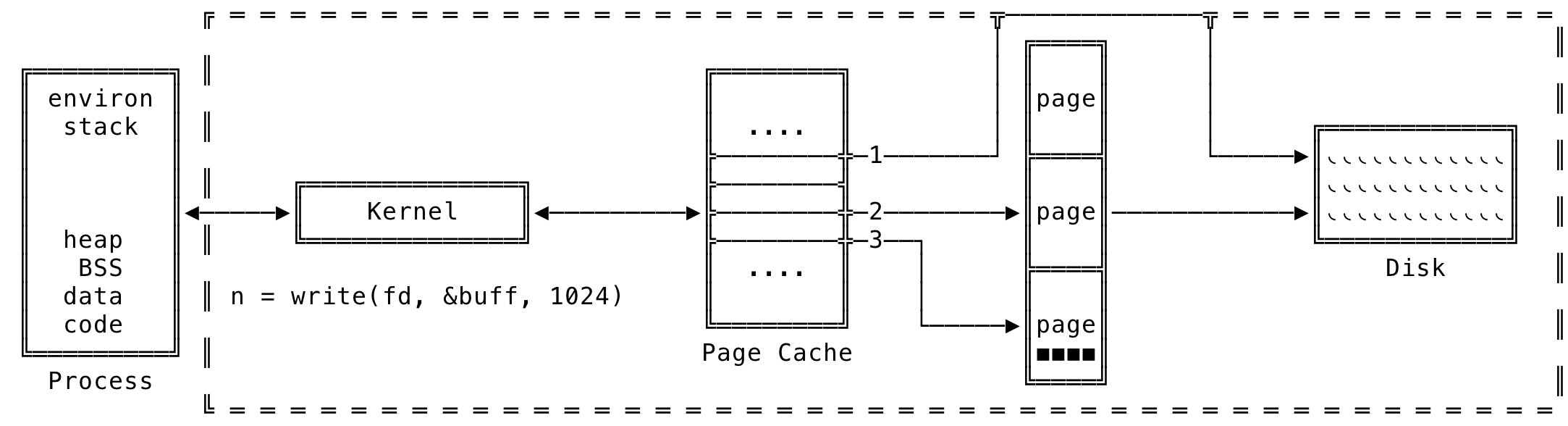
Fig 3: Role of Page Cache during write()
The following shows the dirty pages in the system due to disk I/O. We can then initiate a write back from the shell using the sync command at which point, the kernel will write out all the dirty pages to disk. Now, when we check, there are no dirty pages in the system.
vagrant@ubuntu-bionic:~$ cat /proc/meminfo | grep Dirty
Dirty: 52 kB
vagrant@ubuntu-bionic:~$ sync
vagrant@ubuntu-bionic:~$ cat /proc/meminfo | grep Dirty
Dirty: 0 kB
Cache Size #
The size of cache is only constrained by the amount of free space available in main memory. The kernel imposes no fixed upper limit on the size of the page cache. The kernel will allocate as many page cache pages are needed. If physical memory is scarce, the kernel is responsible for flushing out pages to make space for other processes. This makes sense because the kernel is using space, that is not needed, to speed up operations in the OS. Once other processes want more memory, this space is then made available to them.
Older versions of the kernel used to maintain a separate cache for buffered I/O and page I/O. The new versions of kernel merged them into one single buffer and uses it for both caching purposes. And as explained above, the kernel deals with a page when moving data between disk and main memory. In modern context, buffer cache and the page cache mean the same.
Cache Eviction #
Cache eviction is a strategy used by the kernel to make space either for other page cache entires or make more memory available for processes running in the system. The kernel works by evicting clean (which have not been modified) pages and overwriting them by something else. If there are no enough clean pages to evict, a write-back is initiated for the dirty pages to make more pages available for eviction. The kernel policies defined decide on which pages need to be evicted first. Various strategies are used by the kernel to make the eviction efficient and not evict pages that might be needed in the near future.
Least Recently Used #
An LRU strategy keeps track of when a page is accessed and evicts the page with the oldest timestamp. The kernel keeps track of all the pages in a easily searchable data structure like a list (where the insertion happens on one end while the deletion happens on the other) or as a heap. The underlying assumption is that data that are older will not most likely be used in the near future and can be evicted to make space for newer pages. This approximation actually works well but there are some disadvantages to this kind of eviction strategy. One big failure of this strategy is putting pages that are accessed only once, at the top of the list. The kernel cannot guess the usage pattern of a page unless given hints. This brings us to the modified version of LRU used by Linux.
Two List Cache #
In the two list cache, Linux maintains two lists — an Active and an In-active list. Pages on the active list are not considered for eviction and are considered as very active. Meanwhile, the pages on the in-active list are the ones considered for eviction. Pages are placed on the active list only when they are accessed when residing in the in-active list. That is, the pages are moved up when an page access is made on the in-active list. Both the lists are maintained in a LRU order — the insertion happens on one end whereas the deletion happens on the other. As part of this strategy, both the list are kept in balance, i.e, when the active list gets larger than the in-active list, the older items in the active list are moved to the in-active list. This two list strategy solves the once used page problem that we saw earlier and is also known as LRU/2 cache.
Flusher Threads #
As seen earlier, writes are usually deferred, where in, the changes are applied to the page cache and is acknowledged before written to the disk. These pages, which are not synchronized with the disk are marked as dirty and are supposed to be written back in some amount of time. These dirty page write backs happens due to the following situations:
- On-demand — when the user invokes the
sync()andfsync()system calls in their applications - On low memory situations — the kernel writes back dirty pages to disk. This is because the kernel does not evicts dirty pages. Before evicting a dirty page, the kernel needs to write back the page before considering it. The kernel then can evict the page thereby helping in shrinking the memory
- On specified thresholds breached — the page write back is invoked when for example the threshold for dirty pages is reached. This makes sure that dirty pages does not remain in memory indefinitely
To perform the above write backs, a group of specialized threads are maintained and used by the kernel. These are generally known as the flusher threads. Prior to the kernel version 2.6, the write backs were done by the kernel threads — bdflush and kupdated until they were changed for various performance reasons, post 2.6.
When free memory falls below the dirty_background_ratio value defined, the flusher threads are woken up and are passed the number of dirty pages that needs to be written to disk. The write back will go on until both the following conditions are met: 1) The specified number of pages are written out to disk and 2) The amount of free memory is above the dirty_background_ratio property. The write back stops, when the above both conditions are not true, only when there no more dirty pages to write out to disk.
The flusher thread also wakes up periodically to write out dirty pages, irrespective of the low memory conditions. This is done to prevent data loss in the event of system crashes, where in the changes in the page cache are lost. The flusher thread writes back pages that was modified longer than dirty_expire_interval milliseconds. In this way, the kernel ensures that data gets written periodically and minimizes data loss.
The values for these are other various properties can be viewed in the /proc/sys/vm file.
Flushing Data #
We can force flush output data from the page cache. This feature is mainly used by applications that needs to be acknowledged that the data has been written to disk, or an error — if an error has been encountered. In Linux, synchronized I/O completion means the I/O has been successfully transferred to disk or returns an error.
There are two types of integrity control that Linux operates with, what it means is, there are two types of synchronized I/O completion provided. The differences in the completion comes from the following. Two types of data are associated with any bytes that you read/write. One is the actual data that you read/write and another is the metadata about the file that you are reading/writing. On the disk, both of them are in different sections and the kernel takes care of maintaining it for you. The metadata of a file would be information like, last file access, last modification time, permissions associated with the file, file owner etc.
Coming back, the two types of synchronized I/O completion provided by Linux are: synchronized I/O data integrity completion and synchronized I/O file integrity completion.
Synchronized I/O Data Integrity Completion #
For a read(), the completion happens when the data is transferred from the disk to the process. If the said page was dirty, the page is first written to disk and then a read is made to disk and the data transferred to the process.
for a write(), the completion happens when the data and some of the metadata (we shall see which) is transferred from the process to the disk. The metadata that will be transferred are the ones that allow the data to be read back correctly. For example, the file size needs to be transferred where as the timestamps need not be flushed to disk immediately.
Synchronized I/O File Integrity Completion #
This is a superset of synchronized I/O data integrity completion where in for a read() or a write(), the data along with all of the metadata is read or written to disk.
Now we shall look at the various system calls that can help us perform the different I/O completion.
#include <unistd.h>
int fsync(int fd);
fsync forces a synchronized I/O file integrity completion, where the data along with all of the associated metadata is flushed to disk. It returns only after the data is written to disk and the return value of 0 indicates a success and a value of -1 indicates a failure.
#include <unistd.h>
int fdatasync(int fd);
fdatasync forces a synchronized I/O data integrity completion. Using fdatasync() might reduce the number of disk operations from the two required by fsync() to just one. For example, calling fdatasync() after changing the data, but have a situation where the file size might not change, then there will only be one disk access write made instead of two with fsync(). It returns 0 on success and -1 on a failure.
#include <unistd.h>
void sync();
sync forces all the data and metadata associated with all buffered pages to be written to disk. The call blocks until all buffered data contained in memory are transferred to disk. Another point to note is that sync() is always successful and does not have a return value.
Additional flags can be used together with the open() system call to perform synchronized I/O on a file. The flags to note are O_SYNC, O_DSYNC and O_RSYNC.
#include <sys/stat.h>
#include <fcntl.h>
int fd1 = open("file1", O_WRONLY | O_SYNC);
int fd2 = open("file2", O_WRONLY | O_DSYNC);
int fd3 = open("file3", O_WRONLY | O_SYNC | O_RSYNC);
Here, every write() to file1 will result in flushing the data from the page cache to the disk, with synchronized I/O file integrity completion and an every write() to file2 will result in flushing the data from the page cache to the disk, with synchronized I/O data integrity completion. The O_RSYNC can be used either with O_SYNC or O_DSYNC and provides a similar functionality for the read() system call. When O_RSYNC is used together with O_SYNC, before an read, all dirty pages along with all of the metadata are written out to the disk (synchronized I/O file integrity completion). Then the read() is performed. And when O_RSYNC is used together with O_DSYNC, before an read, all dirty pages along with the associated metadata are written out to the disk (synchronized I/O data integrity completion). Then the read() is performed. More details about the open() system call and its various flags can be seen here.
Direct I/O #
Linux allows you to bypass the page cache when performing disk I/O. The data is transferred directly from the user space to the kernel space. Direct I/O is only helpful for very specialized applications that need more control as to what to write and when. Most databases extensively use direct I/O since they maintain their own buffer pool and manage I/O optimizations and hence do not need an extra redirection by the kernel. Other applications are better off using the kernel to do the buffering for them. Also, the kernel provides much more than just maintaining a page cache. It also performs pre-fetching, performing I/O in clusters of disk blocks and importantly allowing multiple processes accessing the same file to share buffers in the cache.
We can perform direct I/O to a file or a block device (e.g. disk) using the same system calls. We need to pass the O_DIRECT flag when calling open(). Direct I/O was a later addition to Linux and not all file systems support this. If the file system does not support direct I/O, the open() call fails with EINVAL. Also, there are alignment restrictions for direct I/O that need to be followed, since we are performing I/O directly to the disk.
- The data buffer being transferred must be aligned on a memory boundary that is a multiple of block size
- The offset at which the data is written must be a multiple of block size
- The length of the data being written must be a multiple of block size
Advising the Kernel on I/O #
Sometimes applications are in position to advise the kernel about their access patterns. This is possible because the applications themselves might have more context than the kernel itself, and can in-turn let the kernel take advantage of it.
#include <fcntl.h>
int posix_fadvise(int fd, off_t offset, off_t len, int advice);
posix_fadvise system call allows a process to let the kernel know of patterns accessing file data. Important point to note here is that the kernel can follow this advise or not. The kernel can decide on using the advise and optimize the page cache for that process, thereby improving I/O for that said process. The fd is the file descriptor of the disk based file. The offset and length determine the part of file the access is valid for. A length of 0 sets the end boundary to the end of the file from the offset. The advise argument can be any one of the following:
- POSIX_FADV_NORMAL: There is no special advise to the kernel. The process works with the defaults
- POSIX_FADV_SEQUENTIAL: The process expects to read data sequentially. This sets the read-ahead window from 128Kb to 256Kb
- POSIX_FADV_RANDOM: The process expects to read data in a random order. This disables file read-ahead
- POSIX_FADV_WILLNEED: The process expects to use this data very soon. The kernel bring in the data in the boundary specified to the page cache and the process’s subsequent read will be from the page cache. Note, the kernel will hold the pages in memory but will not guarantee for how long. If there are memory constraints on the kernel, it will flush the pages and subsequent access will involve a disk access
- POSIX_FADV_DONTNEED: The process does not expect to use this data any more. If the device is not congested, the data is flushed to disk and then the kernel will try to free the pages used by the data. This will succeed only when there are no dirty pages
- POSIX_FADV_NOREUSE: The process expects to use this data once and then not use it anymore. This tells the kernel that the pages can be freed after it has been accessed once
Again, to re-iterate, these are hints given to the kernel and it is up to the kernel to use them or not.
<stdio.h> Library Buffering #
In addition to the page cache provided by the Linux kernel, the C’s stdio library too buffers data to reduce the number of system call invocations. The library functions use the stdio buffer to cache data before reading/writing data using system calls. The stdio library invokes the read()/write() system call once the stdio buffers fills up or when a fflush() is invoked by the user.
The stdio buffer along with the page cache can be visualized as:
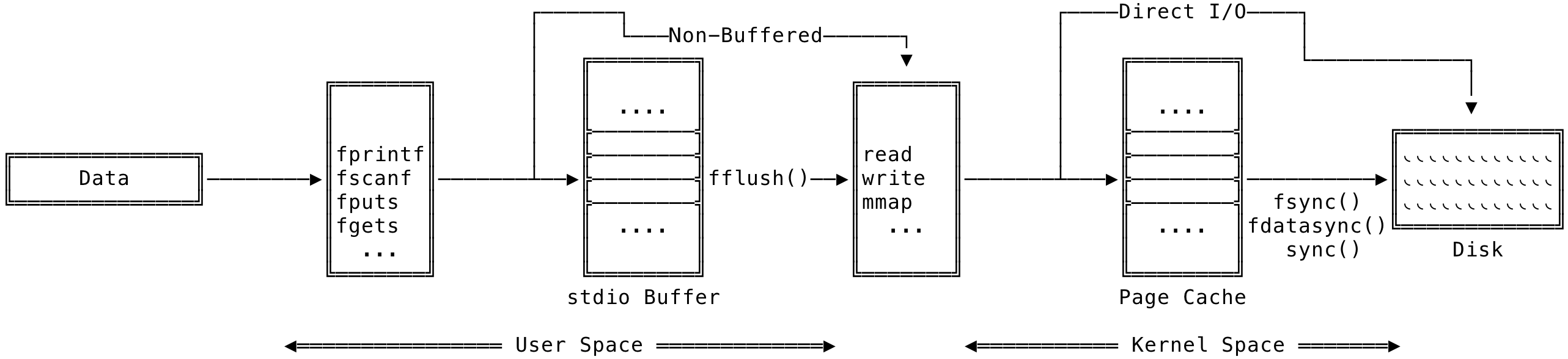
Fig 4: stdio Buffering along with Page Cache
In the above, we can see the data path originating from a process and end on the disk. When using stdio functions, the data first goes to the stdio buffers and then flushed to the page cache, through the system calls, and then finally end on the disk. There are situations where we might want to skip the caches and go straight to the disk. These are called non-buffered or direct I/O. Also, non buffered I/O is the default for stderr — so that the error appears as soon as possible.
Various functions, in the stdio library, helps with controlling the buffering behavior of a file stream.
#include <stdio.h>
int setvbuf(FILE *stream, char *buf, int mode, size_t size);
setvbuf takes a file stream and changes its buffer to the one supplied. size is the size of the new buffer and the mode can be one of the following values:
- _IONBF — This changes the file stream to perform unbuffered I/O. Each stdio call results in the
read()/write()system call - _IOLBF — This changes the file stream to perform line buffered I/O. For output, the data will be buffered until an \n or if the buffer is full, whichever occurs first. For input, the data will be read one line at a time or if the buffer is full, whichever occurs first. For terminal streams, line buffered I/O is the default
- _IOFBF — This changes the file stream to perform fully buffered I/O. This is the default for file streams referring to disk files
Another function, setbuf also takes a file stream and changes its buffer to the one supplied. The difference is that the size of the buffer is BUFSIZ, defined in <stdio.h> and usually has a size of 8K (8192 bytes).
#include <stdio.h>
void setbuf(FILE *stream, char *buf);
As explained earlier, the buffer will be flushed when the buffer is full or the user explicitly flushes the buffer.
int fflush(FILE *stream);
fflush can be used to flush out the buffer for the specified stream. Note, the buffer associated with a stream will also be flushed when fclose() is called on it.
That’s it. Hope this post helps in understanding how the page cache works in Linux. For any discussion, tweet here.
[1] https://www.oreilly.com/library/view/linux-kernel-development/9780768696974/
[2] http://man7.org/tlpi/
[3] https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/