In this blog post, we shall see how a process is represented in Linux. We shall also look at the various data structures, that the OS uses to manage processes, how a process is represented in memory along with its address space, some of its implementation and other finer details.
A process is an instance of a program, which in turn is an executable file. The process is an abstraction over the program that is provided by the OS. The program contains instructions and data that are to be executed for a specific purpose. The process is the actual execution of the said program. In Linux, as in most modern operating systems, many processes can execute simultaneously. This can be instances of the same program or entirely different programs. The kernel performs various bookkeeping and uses various data structures to support running a process. From a kernel’s viewpoint, a process consists of user-space memory containing program code and variables used by that code, and a range of kernel data structures that maintain information about that process. The information contained in the various kernel data structures include identifiers associated with the process, its virtual address space, page tables, open file descriptors, process limits information, parent/child information, one or more threads of execution, processor state etc.
The program - an executable file, aids in the creation of a process by embedding within itself, information like:
- Binary Format Identification: This is the metadata about the format of the executable file. Older executables were in the Assembler Format (a.out) and now mostly the Executable and Linking Format (ELF) is used to encode information about the executable
- Machine Language Instructions: This is the actual program in machine language of the underlying architecture
- Main Routine: The starting address of the program that is to be executed first
- Data: Data about the initialized/uninitialized parts of the program that are to be used
- Symbol Table: This information is used for run-time symbol resolution and debugging purposes. They help in determining the location of a variable within the program
- Shared Library and Dynamic Linking Information: Information about the shared libraries used by the program and the path of the dynamic linker that should be used to load these libraries is contained here
On modern operating systems, processes provides two virtualization - virtual processor and virtual memory. The virtual processor gives the illusion the the process monopolizes the entire CPU, despite sharing the processor with hundreds of other process. This technique is known as time sharing and this allows users to run many concurrent processes.The virtual memory lets the process allocate and manage memory as if it alone owns all the memory in the system. The memory that the process can address is called the address space of the process. The address space acts as a sandbox for that process and the kernel enforces access protection, of that space, from other processes in the system. In this post, we will be concentrating on the how a process is represented and manages memory during its runtime.
Process Creation #
Let us look at how a program comes into existence, as a process, and the role of virtual memory in all of this. To simplify our discussions further, we shall target a x86-32 architecture in this blog post.
How does a process come into existence? How does the OS translate a program, on disk, to a process in memory?
When an executable is run, the OS does the following. The kernel first checks if the resources are available and can support another process. Then a unique PID is assigned to the process and other data structures are created — to support the process during its lifetime. The state of the new process is marked as being created. The address space is created for the process and the executable’s code and data sections are copied over. A context is created for the process to run, the starting address of the executable set and then the new process’s state is marked as Ready — for the CPU to pick it up for scheduling. This can be illustrated as:
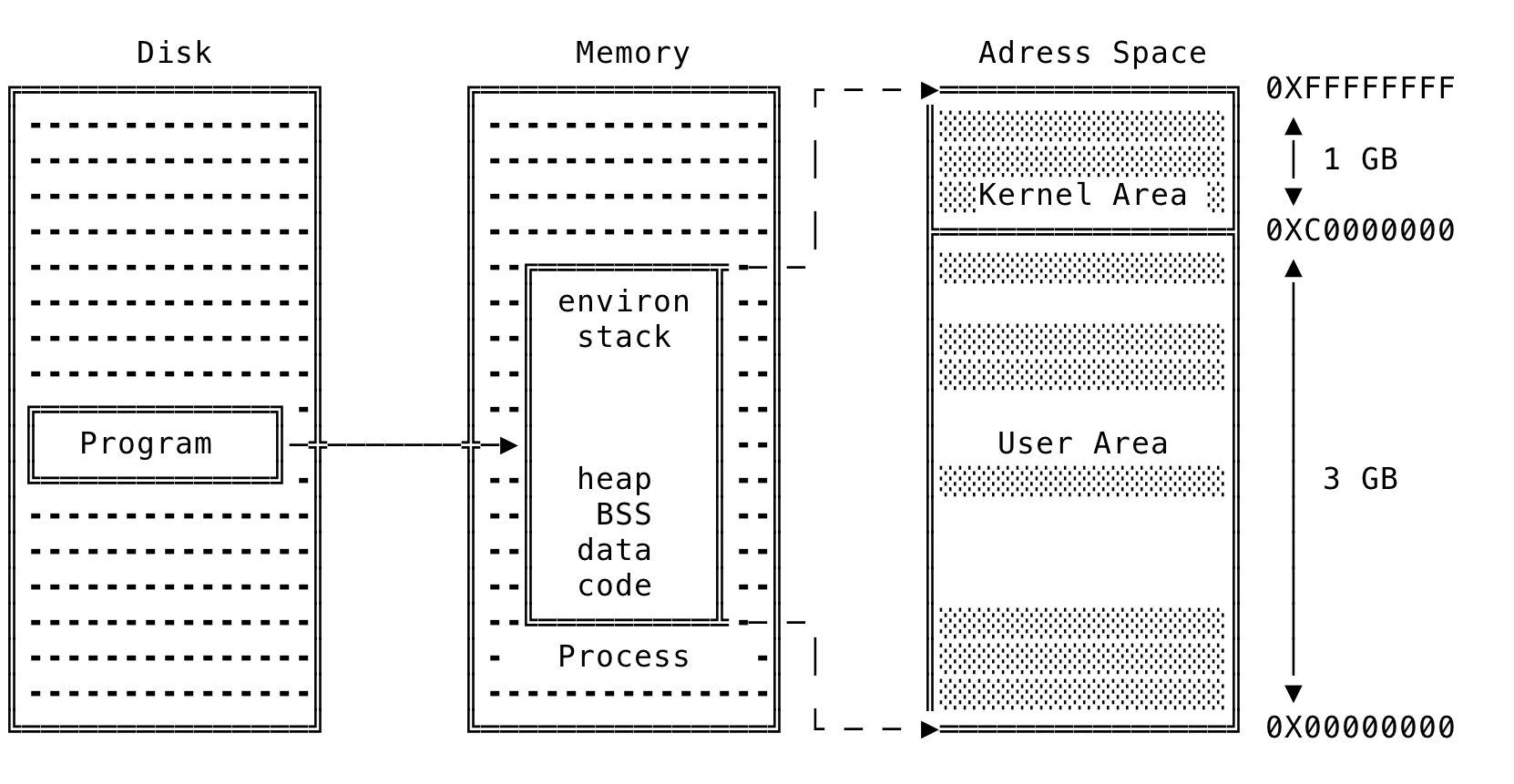
Fig 1: Process Creation
In a x86-32 machine, the total size of a process’s address space is 4GB (2^32 bytes) — which ranges from 0X000000 to 0XFFFFFFFF. The address space as well as the physical memory is divided into equal sized blocks called Pages and these pages in-turn contain the data that is needed by the process. The OS takes care of moving these pages to and fro between memory and disk, using the process’s page tables. We shall look at this scheme in detail below, when we discuss virtual memory. Modern operating systems load the pages lazily, as in when they are needed and not during initialization.
As seen above, the process’s address space is split into kernel area and user area. In a x86-32 machine, 1 GB of the virtual addresses (0XC000000 - 0XFFFFFFFF) are reserved for the kernel. This is because, no matter what the process context, kernel pages should always be available to the OS to work with. That is — the kernel’s pages are always present and maps the same physical memory in all the process and does not change across process context switch. This space contains privileged code and if a user-mode process access them — it results in a segmentation fault. 3GB of the virtual addresses (0X00000000 - 0XBFFFFFFF) are available to the process for its pages. Linux has demand paging and hence does not need all pages to be in memory at a given time. The shaded regions in the process’s address space represents addresses that are mapped whereas the non-shaded region represents unmapped memory. The process’s address space is further divided into various segments that will be explained later in this blog post.
Virtual Memory #
The abstraction over physical memory, provided by the OS, is simple. Memory is just an array of bytes to read/write. To read/write, a memory address must be specified and the operation will be performed on that said address. Further, the OS virtualizes memory and provides, for each process, its own private virtual address space. The OS takes care of mapping the virtual addresses to physical frames in memory and the process works only with virtual memory.
As explained above, the size of the process address space, for a 32-bit machine, is 4GB (2^32) — ranging from 0X000000 to 0XFFFFFFFF. Also, 1 GB of the addresses (0XC000000 - 0XFFFFFFFF) is reserved for the kernel and cannot be used by the process for its use.
The OS treats the Page as the basic unit of memory management. A virtual memory abstraction splits the memory used by each process into small fixed size pages. The physical memory is also split into the same fixed sized units. Although the processor’s smallest addressable unit is a word, the Memory Management Unit (MMU) — the hardware that manages memory and performs virtual to physical address translations, along with the kernel deals with pages. A page is typically 4K/8K in size.
The page size of a machine can be found by running the following command:
$getconf PAGE_SIZE
Linux uses demand paging. At any time, only some of the pages of the process needs to be in memory. The pages in physical memory at a given time is called resident set of the process. The unused pages are present in a area called a swap space, a reserved area on disk. In Linux, a particular page is served on demand - when a process tries to access the page that is not in memory. When an access is made to a page not in memory, a page fault is raised, at which point the kernel suspends execution of the process to transfer the page from swap to memory. Also, most programs demonstrate some kind of locality. Hence, when a page is being served, the OS also brings in pages, that it thinks that the process might need in future. If an access is made for an address for which there is no corresponding page table entry, a SIGSEV signal is raised and the program crashes.
The data structure that the OS uses, to represent a page, contains various information that helps the kernel better manage them. Each page is associated with a set of flags. These flags stores the status like if the page is dirty or not, if the page is under write-back, or if the page is locked in memory etc. The kernel also maintains the count of the number of references to the page where 0 means it can be swapped back and re-used. It also contains the virtual address of the page and also has with it the index number into the page table, which is used for address translation.
These information about a page helps the kernel track the validity of the data and also use it for efficient replacement policies. Replacement policies kick in when the kernel wants to bring in a page and finds that there are no empty page slots left. The replacement algorithm is then responsible for choosing a page to swap out to disk to make way for the new page. Least Recently Used (LRU) is the most common policy used by the kernel to swap out pages to disk to make way for new pages. And if the selected page is dirty, that is the data in the page has been modified, a write-back is invoked before swapping out the page to the swap area.
Multiple processes can share memory among each other. For example, two processes can share the same code and hence share the corresponding pages. This is made possible by the different page table entries of the processes pointing to the same pages in the physical location. There can be only one copy in memory and this can be shared by all dependent processes. For example, there is only one copy of the C library in memory and all the C programs use this copy.
A process’s virtual address space is dynamic. The kernel allocates and de-allocates pages for the process during its lifetime. And since, only part of the process needs to be in memory at a time, more process can be held in memory. This also results in better CPU utilization, since at a given point in time, the CPU can spend its time executing any given process and not remain idle for long.
The kernel maintains a page table per process and the Memory Management Unit (MMU) along with the kernel use it to do the translation of a virtual address to its corresponding physical address. When a process is context switched, the page tables are also switched to point to the current process’s page table entries. The isolation of the virtual address space is made possible by having separate page table entries for each process.
Assuming the page size in the system is 4KB and a X86-32 system, the total address space would be divided into 1048576 distinct pages ((2^32) / (4 * 1024)) numbered from 0X00000(0) to 0XFFFFF(1048575). The logical separation can be visualized as:
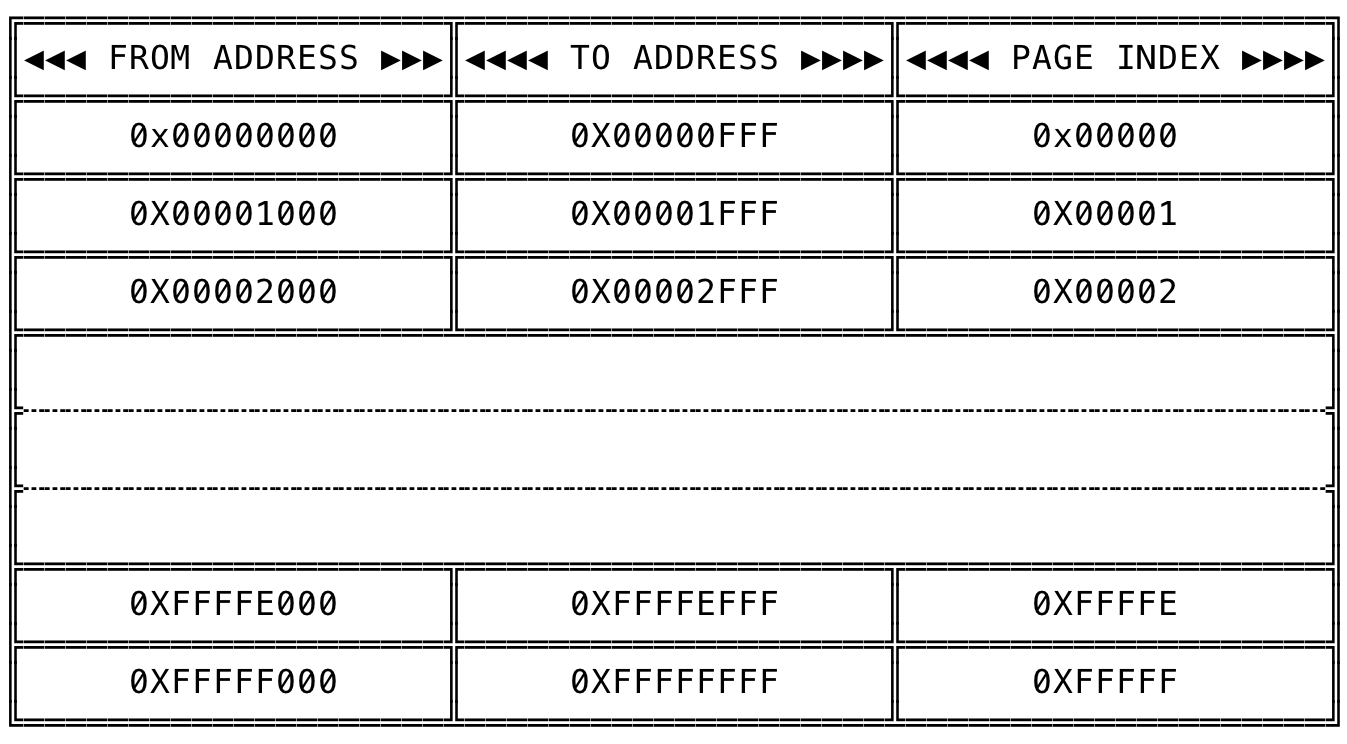
Fig 2: Division of Page Table
Virtual To Physical Address Translation #
Whenever we read/write to memory, the CPU translates the virtual address to its corresponding physical address. The virtual address is split into two parts: the page index and the offset. The CPU’s Memory Management Unit (MMU) uses the page table of the process to translate the virtual address to its physical address. The page table is maintained by the OS and is present in memory.
In a X86-32 machine, with a 4KB page size, out of the 32-bits, the first 20-bits represent the page index (Since there are [ (2^32) / (4 * 1024) ] = 1048576 pages, and we need 20 bits [2 ^ 20 = 1048576] to represent 1048576 pages) and the next 12 bits is used as the offset in a given page (Since a page size is 4096, we need 12 bits [2 ^ 12 = 4096] to represent 4096 addresses in the page). So, for an address like 0X1234FFFF, the address 0X1234F will point to the page index of the page table and the address 0XFFF will point to the offset in that page.
The address translation works like one shown below:
Fig 3: Address Translation
Let us take the same above address to see how the translation works. 0X1234FFFF is the address that needs to be translated to its corresponding physical address. Let us also assume that the page table entry corresponding to page at index 0X1234F, is 0XAAAAA. This value is taken and left shifted and ORed with the offset to give the address 0XAAAAAFFF, which is the physical address of the data to read/write.
Pages faults occur when an access is made to pages not mapped in physical memory. The OS handles the page fault and checks if the access is made to an allocated but swapped out page or an unallocated/invalid page. If it is for a swapped out page, the OS brings in the page to memory and returns the control back to the OS. If the access was made to an unallocated/invalid page, the process is a segmentation fault (SIGSEV) and a core dump is created, if configured.
A cache is made available to the CPU to fast convert a virtual address to its corresponding physical address. A limited sized table, Translation Lookaside Buffer (TLB) is used to speed up this translation. This scheme is made available under the assumption, that a process will reuse pages during its lifetime rather than access them randomly. When an access is made to a page, the CPU checks the TLB to see if it had accessed the page recently. If present, it returns the value immediately. If an entry is not present, it then looks at the page table to find the corresponding value and stores it in the TLB for future access. And since, the TLB is closer to the CPU, this operation is orders of magnitude faster than accessing the page table for the same address.
Linux also supports over-committing, where in a process can use more memory than what is available in the entire system. The MMU takes care of translating such virtual addresses to the actual physical address. The OS supports over-committing by the fact that not the entire pages of a process needs to be in memory at a time and hence can use demand paging to support such use cases.
Process Layout In Memory #
A process’s memory is split into various contiguous areas called segments. A process, in Linux, is usually split into the following segments as illustrated below:
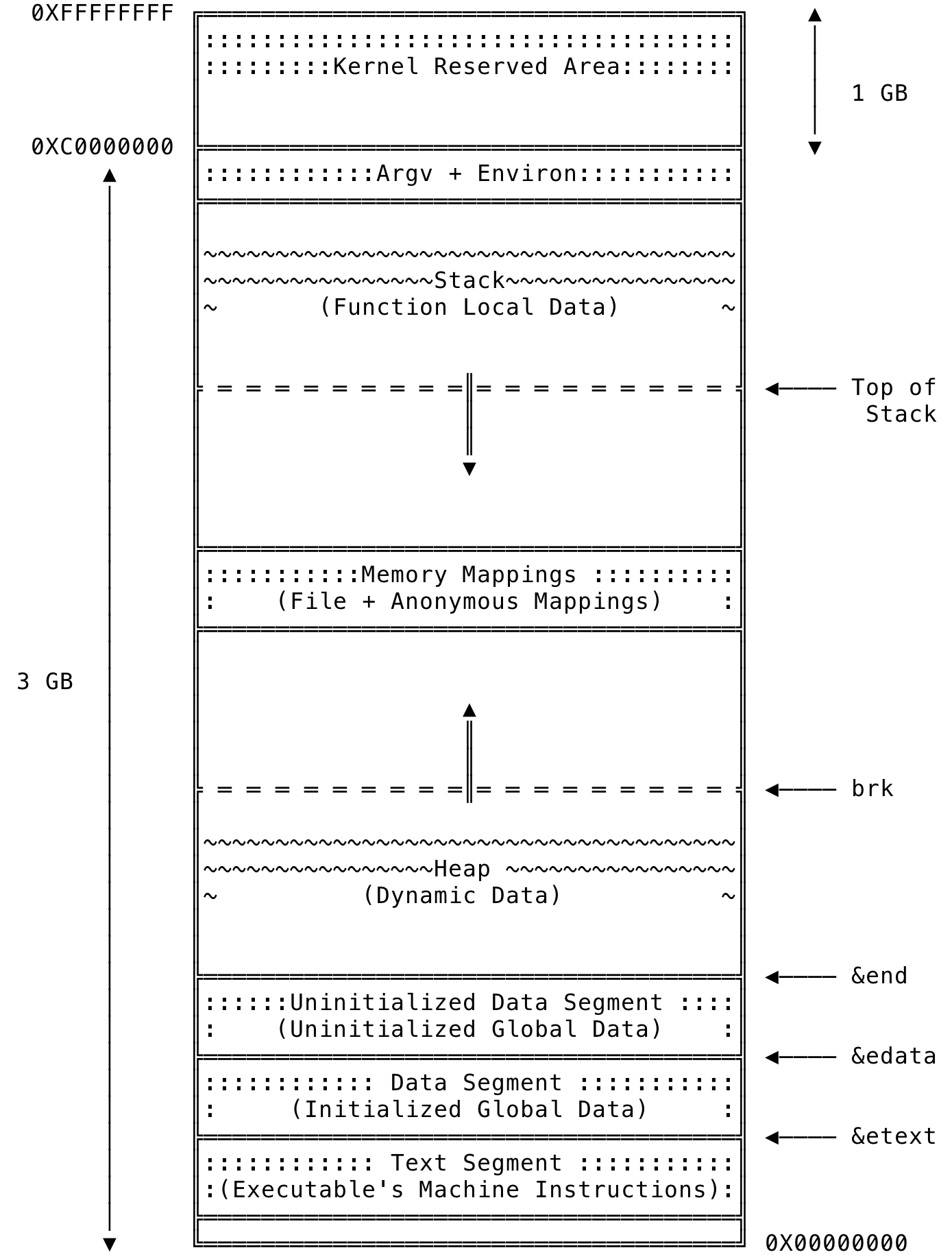
Fig 4: Process Segmentation
Let us look at the various segments in more detail.
- Text Segment: This segment contains the machine language instructions of the executable. The text segment is a read only segment and a this cannot be changed during the runtime of the process. Any write made to the memory address in this area results in a segmentation fault. Many process can share the same instructions, since they may be running the same program. This is achieved by having a single copy of the program mapped to a physical memory and every process mapping it on to its own address space.
&etextis the address of the next byte past the end of the text segment - Data Segment: This segment contains the initialized global and static data of the program. This is read from the executable and the memory needed for each of the variables are allocated and initialized to the values given in the program. This segment is writable and the
&datais the address of the next byte past the end of the data segment - Uninitialized Data Segment (BSS): This segment contains the global and static variables that are not initialized. This entire segments is initialized to zero (0). Historically, this was called Block Started by Symbol (BSS) and might be interchangeably called as such. A separate segment in this case helps by recording the count of global/static variables needed and not store each variable and initialize it to 0. The loader will reserve the space for the variables when it boots up from disk. This segment is writable and
&endis the address of the next byte past the end of the uninitialized data segment - Heap: A process usually needs to allocate memory dynamically during its runtime. The memory allocated as such resides on the heap and the process can read and write to such memory areas. A process can allocate memory by increasing the size of the heap. This area grows and shrinks as memory is allocated and freed. The end of the heap is represented by the
brkpointer and managing the heap is as simple as adjusting this pointer. The OS providesbrk()andsbrk()system call to manage the heap and the C library functions likemalloc()and others are implemented on top of the said system calls. Most languages provide calls implicitly or explicitly to manage heap memory. - Memory Mappings: This segment contains the contents of the file that are directly mapped to memory. Using memory mapped I/O is sometimes faster when working with I/O intensive applications. Also, the shared dynamic libraries are memory mapped into the process’s address space and the pages of such libraries are shared across processes. This area also contains anonymous memory mappings, where in the mappings are not backed by any file and instead used for program data. This is similar to the data present in heap and implementations of
malloc()creates a memory mapped region — for large memory requests. A memory mapping can be created using themmap()system call and un-map the same using themunmap()system call. - Stack: Like the heap, this segment too grows and shrinks linearly as functions are called and returned from. This segments contains the variables and data contained within a function. For each called function, a stack frame is allocated and is used to store the data within the method’s context. A single frame stores the function’s local variables, arguments, return value etc. And when the function returns, the stack frame is popped and data erased (technically re-used). In most Linux implementations, the stack grows from a higher memory address to a lower memory address. A special purpose register — stack pointer is used to keep track of top of the stack.
- Environment and Command Line Args: This segment contains the environment and command line arguments passed to a program. The environment variables get passed from the parent process or can be a clean slate depending on the system call used to create a process. The child process can then append/override them. The command line arguments and the environment variables for a process can be examined using the following commands:
# To view the command line args of the process
$cat /proc/<PID>/cmdline
# To view the enviroment variables of the process
$cat /proc/<PID>/environ
To better understand the various segments, its boundaries and what variables are placed where - we will make use of the below program to better illustrate our explanations above.
When running the above program, we get an output similar to the one shown below:
Next byte past:
etext 0x5587364289fd
edata 0x55873662902c
end 0x558736629040
Program Break:
brk 0x5587374a6000
Address:
a 0x558736629010
b 0x558736629030
c 0x558736629014
d 0x558736629034
e 0x558736629028
f 0x558736629038
g 0x7ffd5fb8119c
s 0x558736629018
p 0x558737485260
We can see that the variables are placed in their respective segments as discussed above. The address against etext, edata and end correspond to the next byte past the text segment, data segment and the uninitialized data segment. The address against brk corresponds to the end of the heap segment. We can then see the address of other variables against these boundaries. The variables a, c, s and e are placed in the initialized data segment, as seen from the addresses. Where as, the variables b, d and f are placed in the uninitialized data segment. Variable g is scoped to the main function and is hence placed in the stack segment. The variable p is a pointer to the dynamically allocated memory and is placed in the heap segment, as can be compared with the address of brk.
Although the variable s is allocated on the initialized data segment, the string Hello World!!! is stored in the text segment. A read only variable using this string will only contain a reference to the string originally in the text segment where as a variable capable of changing its string content will initially point to the original string in the text segment, but will point to the changed string when modified.
Another important point to note - since the structure of the process in memory is the same as the one shown above - some address space randomization has been introduced to thwart attacks that take advantage of this structure. Hence, the address of the segments are randomized by adding random offsets to the starting address of such segments.
Kernel Representation of Process #
We shall now look at how kernel represents a process and also the various data structures it uses to manage the processes.
The kernel represents the list of processes as a circular doubly linked list, called the Task List. (In Linux, another name for a process is a task). Each element in the doubly linked list is a process descriptor of type struct task_struct. This struct is defined under the <linux/sched.h> header file. (You can check out all the fields under task_struct here)

Fig 5: Task List
The task_struct structure is quite large and contains all the information about a process. It contains task information like state of the process, priority, pending signals, parent/children, the process’s virtual address space, open files etc.
For example, you can use the macros provided to iterate over all tasks and read all the information about the processes in the system:
struct task_struct *task;
for_each_process(task) {
// Use the task information
}
The kernel uses the slab allocator to allocate task_structs, for use by the various processes. The slab allocator is an allocator used within Linux to facilitate frequent allocations and deallocations of data structures required by the kernel. A free list is maintained by the allocator - where in the list contains already allocated data structures. When the kernel needs a instance of the data structure, it can grab one of the free list rather than allocate the sufficient memory and set it up for use. More details and implementation of the slab allocator can be found here.
Linux implements fork(), vfork() and __clone() system calls through the clone() system call. The clone() system call in-turn calls do_fork(). do_fork() then calls copy_process() to takes care of creating a new task_struct for the process and initializes it to the state that the caller wants. Some of the work that copy_process() does is as follows:
dup_task_struct()is called which creates a new kernel stack, thread_info struct and the task_struct for the new process. The child’s state is identical to its parent and at this point and both the descriptors are the same- To differentiate the child from its parent, some of the process descriptors are changed. Majority of the task_struct state of the child are still identical to its parent
- Calls
alloc_pid()to assign the next available PID to the child - Depending on the flags passed, open files, signal handlers, process address space etc are either shared or duplicated
Note, Linux does not differentiate between a process and thread. Threads provide multiple paths of execution within the program, in a shared memory address space. For the kernel, there is no concept of a thread. Linux implements all threads as a standard process. It does not provide any special scheduling semantics or special data structures for threads. A thread, in Linux, is merely a process that shares certain resources with other processes. Each thread has a unique task_struct and it shares the address space with other processes. Threads are created as a normal process and the clone() system call is passed the flags specific to the request. For example, clone() is called with the following options:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
Here the address space, filesystem resources, file descriptors and signal handlers are shared between the parent and child. In Linux, the new child is what is called a thread.
When a process is terminated, the kernel releases the resources owned by the process and notifies the child’s parent of its termination. The do_exit() method performs the bulk of the work when a process is terminated. It performs work like releasing the address space, quit waiting for any locks/semaphores, sending signal to the parent, reduce usage count of various file descriptors that were used etc. When do_exit() returns, the process descriptor still exists and the process becomes a zombie. Once the parent has extracted the child’s termination information, the child’s task_struct is deallocated and returned back to the slab allocator. At this point, all resources associated with the child has been freed up.
Kernel Representation of a Process’s Address Space #
As explained earlier, the address space of a process is the representation of the memory given to a process. Linux uses virtual memory and hence the memory is virtualized across all the processes in the system. A process’s view is that it owns all the memory in the system and the OS takes care of translating this virtual address to the actual physical address. The size of the address space depends on the architecture. For a 32-bit machine, a process is provided with a 4GB address space (2 ^ 32).
A memory read/write is identified by a memory address. Although, for a 32-bit machine, 4GB of address space is available, not all of this memory can be addressable by the process. Only the intervals (called segments, as seen earlier) like the text, data, heap, stack etc does the process have permission to access. These intervals, of valid addresses that the process can access, are called Virtual Memory Areas.
The kernel can dynamically add and remove memory areas to a process’s address space. The process can read/write to addresses within a valid memory area. The virtual memory areas, and the pages inside them, have associated permissions - such as readable, writeable, executable. For example, the text section of a process has read-only along with executable permissions associated with it. Accessing a memory address outside valid memory areas results in a segmentation fault for the process.
The kernel represents the virtual memory address space through a data structure called the memory descriptor. This memory descriptor is represented by the struct mm_struct data structure, defined in <linux/mm_types.h>. This struct contains all the information about the address space like the list of memory areas, no of users of the address space, start and end address of various memory areas etc. (You can check out all the fields under mm_struct here)
A process’s task_struct has a reference to the mm_struct contained within. The mm_struct is said to be the memory descriptor of the process and represents the process’s address space.
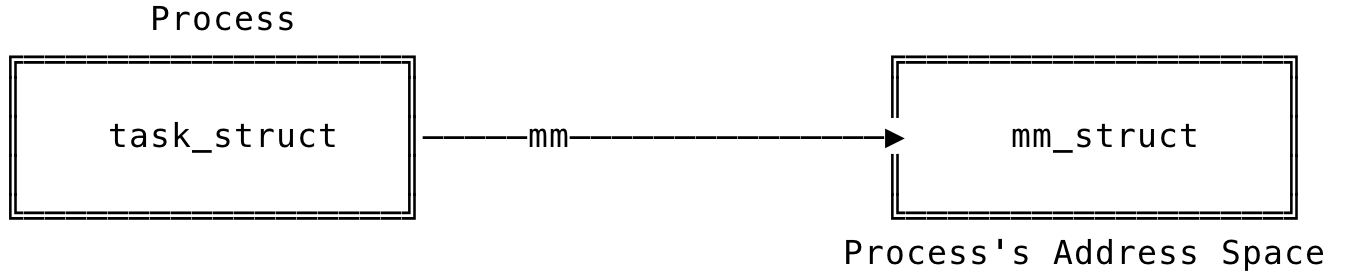
Fig 6: Memory Descriptor
The task’s mm field contains the reference to the memory descriptor. The mm_struct data structure, like the task_struct, is allocated using the slab allocator using the allocate_mm() macro. During the fork() system call, the copy_mm() function is used to copy the parent’s memory descriptor to its child.
When the process terminates, the exit_mm() function is invoked. This function performs cleanup and decreases the user count for the address space. When the the number of users get to 0, the free_mm() function is called and the mm_struct is deallocated and returned to the slab allocator.
The mm_users field in the mm_struct denotes the number of process using the address space, represented by the mm_struct. Whereas, the mm_count is the reference count of the address space. For example, if five threads use an address space, the mm_users is five but the mm_count is only one. When the mm_users count reaches 0, the mm_struct is freed.
The pgd field contains the page tables for the process, map_count contains the number of virtual memory areas for the process. The mm_struct also contains the cache to the last accessed memory area and the first address space hole. Also, the structure additionally contains the start and end addresses of code, data, heap, stack and environment segments.
The most important fields are probably the mmap and mm_rb fields. They both refer to the same data - all virtual memory areas of the address space. The difference is that the mmap filed stores the VMAs in a linked list whereas the mm_rb fields stores the VMAs using a red-black tree. Different data structures are needed to support different types of operations on the VMAs. The list is good for iterating over the memory areas whereas the red-black tree is good for searching. Note, the kernel does not duplicate these two structures, but instead overlays a tree into a red-black tree.
Virtual Memory Areas #
Each virtual memory area(VMA) of the process is represented using a vm_area_struct data structure, defined in the <linux/mm_types.h>. A single virtual memory area describes a address range over a contiguous interval and is treated as a single block. Permissions like read, write and execute is associated with a memory area, depending on the which segment of the process they represent.
As discussed above, the mmap field contains a list of the various memory areas of the process. The list of various memory areas can be visualized as below:
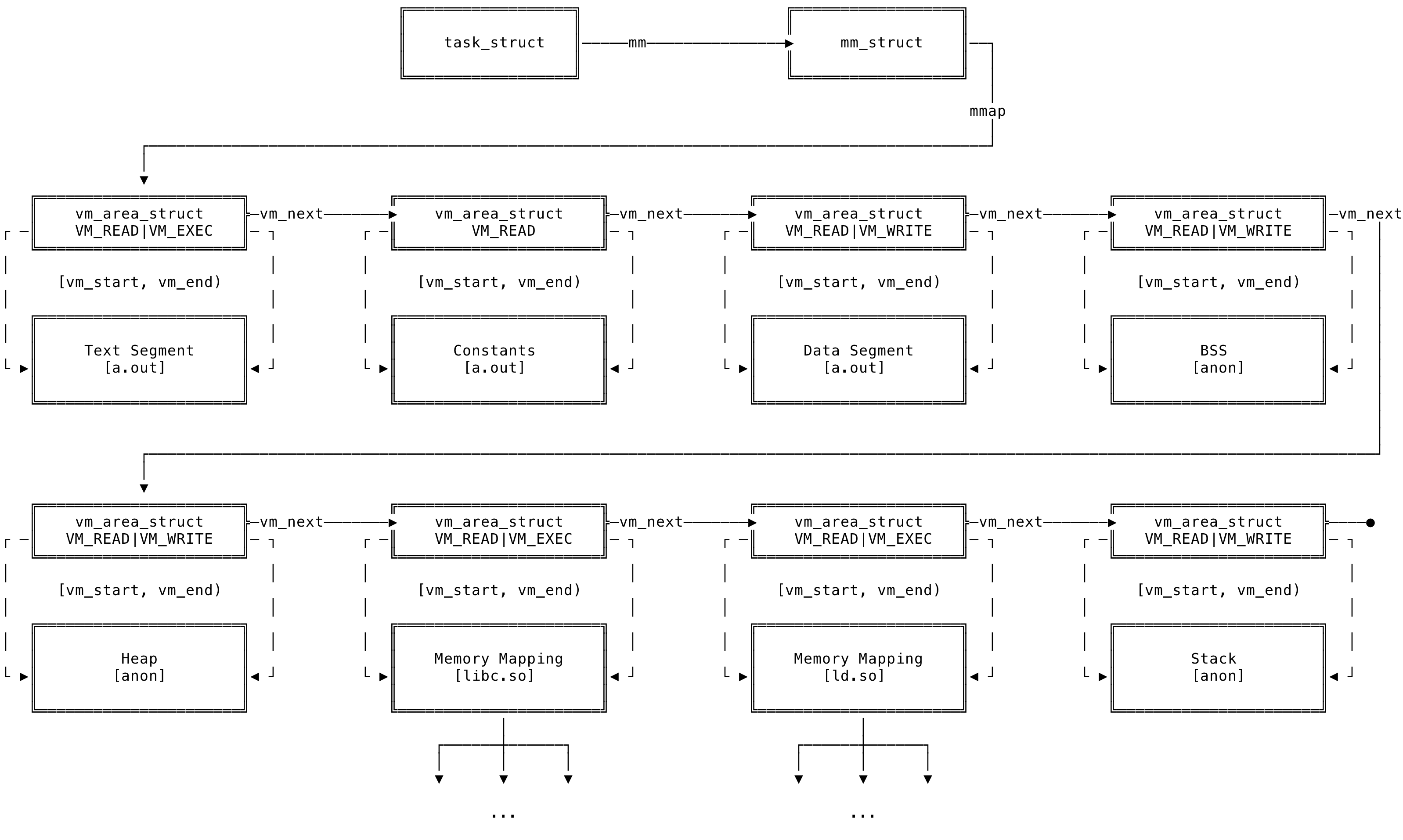
Fig 7: vm_area_struct Representation
The vm_start field of the vm_area_struct is the start address of the memory area and the vm_end is the first byte after the end address of the memory area. Addresses within the area is of the range [vm_start, vm_end). vm_end - vm_start is the length of the memory area in bytes. The pages within the VMA have the same permissions of the memory area. The permissions do not overlap and if some pages need different permissions, the main memory area is broken up into smaller areas with different permissions. In the above example, the executable (a.out) is broken into different memory areas depending on the access permission on the pages within that memory area. It is broken into the text, data, BSS etc. and all the pages in the segments are of uniform permissions.
The virtual memory areas can be backed by a file or can be anonymous. In our example above, the BSS, heap and the stack memory areas are not backed by any file and are anonymous. The memory mappings has a readable and non writable memory areas representing the C library and the dynamic linker. Since this is not writable, the kernel can have only one copy of the pages of libc and ld and share them across all process using them. The memory mappings of libc and ld contains within it its text, data, BSS, stack and heap sections.
You can use various command line utils to print out the virtual memory areas of a program. You can use the output from /proc/<PID>/maps to check out the various memory maps of the process.
vagrant@ubuntu-bionic:~/Projects/Process$ cat /proc/7272/maps
558680331000-558680332000 r-xp 00000000 08:01 263150 /home/vagrant/Projects/Process/a.out
558680531000-558680532000 r--p 00000000 08:01 263150 /home/vagrant/Projects/Process/a.out
558680532000-558680533000 rw-p 00001000 08:01 263150 /home/vagrant/Projects/Process/a.out
55868136f000-558681390000 rw-p 00000000 00:00 0 [heap]
7f09fd60f000-7f09fd7f6000 r-xp 00000000 08:01 2083 /lib/x86_64-linux-gnu/libc-2.27.so
7f09fd7f6000-7f09fd9f6000 ---p 001e7000 08:01 2083 /lib/x86_64-linux-gnu/libc-2.27.so
7f09fd9f6000-7f09fd9fa000 r--p 001e7000 08:01 2083 /lib/x86_64-linux-gnu/libc-2.27.so
7f09fd9fa000-7f09fd9fc000 rw-p 001eb000 08:01 2083 /lib/x86_64-linux-gnu/libc-2.27.so
7f09fd9fc000-7f09fda00000 rw-p 00000000 00:00 0
7f09fda00000-7f09fda27000 r-xp 00000000 08:01 2079 /lib/x86_64-linux-gnu/ld-2.27.so
7f09fdc1e000-7f09fdc20000 rw-p 00000000 00:00 0
7f09fdc27000-7f09fdc28000 r--p 00027000 08:01 2079 /lib/x86_64-linux-gnu/ld-2.27.so
7f09fdc28000-7f09fdc29000 rw-p 00028000 08:01 2079 /lib/x86_64-linux-gnu/ld-2.27.so
7f09fdc29000-7f09fdc2a000 rw-p 00000000 00:00 0
7ffda246f000-7ffda2490000 rw-p 00000000 00:00 0 [stack]
7ffda257f000-7ffda2582000 r--p 00000000 00:00 0 [vvar]
7ffda2582000-7ffda2584000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
The data is of the format start-end|permission|offset|major:minor|inode|file. Another util, pmap can also be used to look at the various memory areas and is called with pmap <PID>. The output is of the form,
vagrant@ubuntu-bionic:~/Projects/Process$ pmap 7272
7272: ./a.out
0000558680331000 4K r-x-- a.out
0000558680531000 4K r---- a.out
0000558680532000 4K rw--- a.out
000055868136f000 132K rw--- [ anon ]
00007f09fd60f000 1948K r-x-- libc-2.27.so
00007f09fd7f6000 2048K ----- libc-2.27.so
00007f09fd9f6000 16K r---- libc-2.27.so
00007f09fd9fa000 8K rw--- libc-2.27.so
00007f09fd9fc000 16K rw--- [ anon ]
00007f09fda00000 156K r-x-- ld-2.27.so
00007f09fdc1e000 8K rw--- [ anon ]
00007f09fdc27000 4K r---- ld-2.27.so
00007f09fdc28000 4K rw--- ld-2.27.so
00007f09fdc29000 4K rw--- [ anon ]
00007ffda246f000 132K rw--- [ stack ]
00007ffda257f000 12K r---- [ anon ]
00007ffda2582000 8K r-x-- [ anon ]
ffffffffff600000 4K r-x-- [ anon ]
total 4512K
address|kbytes|RSS|dirty|permissions|file. The utils essentially iterate over the mmap list to print out the areas and its properties out to the console. More details can be found here — mmap and proc.
That’s it. Hope this post shed a few details about how the OS creates and manages a process. We also took a look at how the process’s address space is being managed by the kernel and also what data structures it uses to manage the same. Hopefully, I will add more posts about how Linux works under the hood :)
For any discussion, tweet here.
[1] http://man7.org/tlpi/
[2] https://manybutfinite.com/post/anatomy-of-a-program-in-memory/
[3] https://www.oreilly.com/library/view/linux-kernel-development/9780768696974/