In Linux, virtual memory is the software controlled memory abstraction that allow each process to maintain its own address space. The user processes work with virtual memory and the kernel is responsible for translating the virtual memory into its corresponding physical address — in order to read and write data. The virtual address of a process is valid only within its own context and the same virtual address will mean something else in a different process’s context.
The address space of a process is the amount of memory that a process can read/write to. The size of the address space is dependent on the CPU register size. 32-bit machines have an address space of - 2 ^ 32 bytes and 64-bit machines have an address space of - 2 ^ 64 bytes. Note - not all this memory is addressable by the process, because the total addressable memory is divided into user and kernel areas and a process can address only those within the user area.
Virtual memory subsystem is responsible for lazy allocation, file backed mappings, copy-on-write behavior, swapping etc and in this post we shall look at each of its functionality in detail and also what other sub-components the kernel makes use of, to provide the virtual memory abstraction. For a higher level overview of how a process is represented in memory, you can refer to my previous blog post. In this post, we will focus on the internals of virtual memory abstraction alone.
The kernel uses physical addresses to read/write data directly to memory or to a device. All virtual address get passed to the Memory Management Unit (MMU) that converts the virtual address to its corresponding physical address. This unit is also responsible for raising a fault for the software fault handler to handle. This aids most of the functionality provided by virtual memory. The MMU makes use of the per-process page table to resolve a virtual address. A very high level workings of a MMU can be seen below.
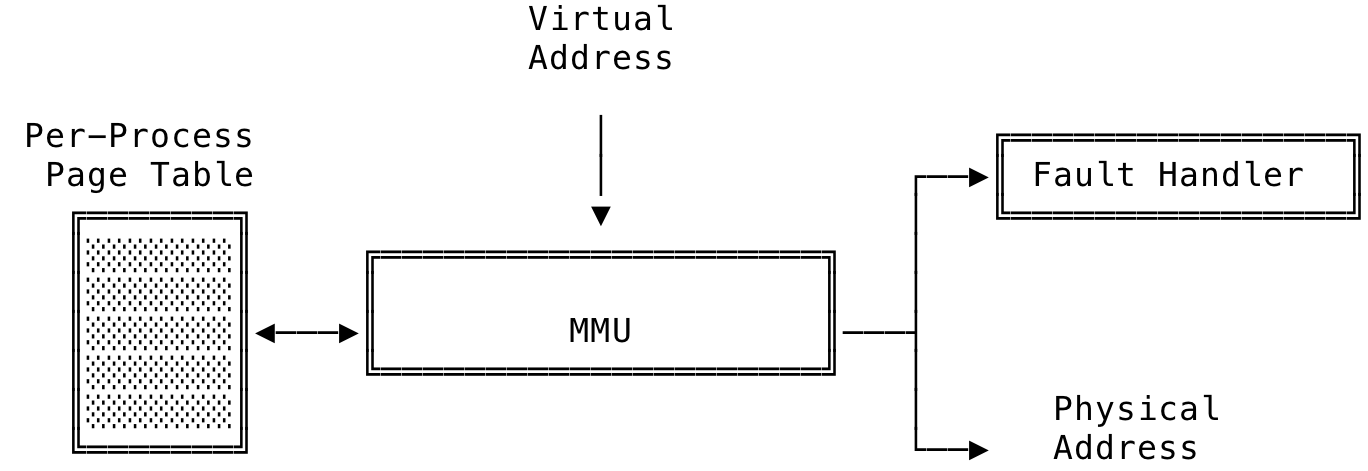
Fig 1: MMU at a High Level
The page table is specific to a process and it aids in translating a virtual address to its corresponding physical address. The page table contains a process’s list of memory mappings and some additional info associated with it, like the starting address of the mapping, length, permissions etc. The number of entires in the page table depends on the CPU register size. On a 32-bit machine and a page size of 4K, the max number of entries in the page table equals 1048576 (2^32 / (4 * 1024)). So, given a 32-bit virtual address, the first 20 bits specify the index into the page table. The next 12 bits specify the offset in that address. The below is a sample translation of a virtual address to its physical counterpart.
Fig 2: MMU Virtual Address Translation
The virtual address passed to the MMU is 0X1234FFFF. The first 20 bits are used to index into the page table to get the starting address of that page in memory. Let us assume that the value at 0X1234F is 0XAAAAA. This is used by the MMU and is suffixed with the rest of the bits (12 bits) of the virtual address, which is used as the offset, to get the complete address in memory - 0XAAAAAFFF. The requested data’s page starts at memory address - 0XAAAAA and 0XFFF is the offset into that page that contains the requested data.
At a higher abstraction, the translation would look something like (assuming a 32-bit machine with a page size of 4K):
def translate(v_add):
# We need the first 20-bits to index
# into the page table
mask = 4294963200 #(2**32) - (2**12)
# mask in binary = 0b11111111111111111111000000000000
# Bitwise AND with mask and shift 12-bits
index = (v_add & mask) >> 12
page_start = page_table[index]
if page_start is None:
# Page table entires associated with the address
# is also passed, but to keep this simple
# the below should do
raise PageFault(v_addr)
# return page_start and the last 12-bits
# of v_add
mask = 4095 #int('111111111111', 2)
offset = v_add & mask #get last 12-bits
page_start = page_start << 12 #make space for last 12-bits
# Physical address is the combination of start, offset
p_add = page_start | offset
return p_add
Memory Mappings #
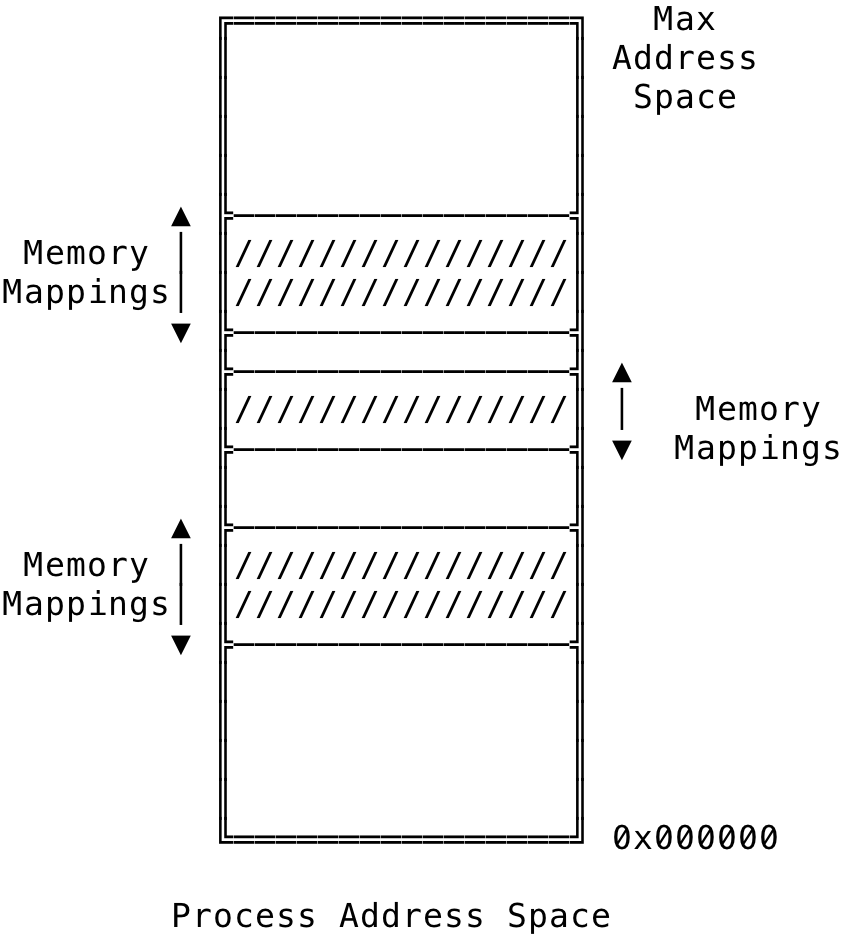
Fig 3: Memory Mappings in a Process
A memory mapping is a continuous range of memory addresses within a process address space. The process’s page table contain various properties about the memory mappings and this information is used by the kernel to manage page faults for the process. Each memory mapping contains the start address of the mapping, the length and the necessary permissions of the mapping among various other information. This enables the kernel to support lazy allocation, file mappings, copy-on-write, swapping and a much more rich feature set.
A memory map can be created through the kernel using the mmap() or brk()/sbrk() system call. A munmap() is used to discard a memory mapping. malloc() and other C standard library calls internally call them to create memory mappings with a process’s address space. A memory mapping can be anonymous, file backed, copy-on-write or shared.
Memory mappings created are lazily allocated physically. When a memory mapping is created, only virtual addresses are created — these are essentially new page table entries (PTE) added to the process’s page table. No physical memory is allocated and they are created on-demand during access. The page table entries of a particular process contains all the information related to mappings created by that process. The MMU and the page fault handler works in tandem to allocate physical memory during runtime, using these entries.
Access to virtual addresses in the address space not mapped — said to be unmapped, will result in a Segmentation Fault with a SIGSEGV sent to the process.
More details about mmap() can be found here. Please check out my earlier blog post for details of the process’s various memory mappings.
We shall now look at how the page fault handler works with the MMU to enable various virtual memory features.
Page Fault Handler #
The page fault handler is part of the Memory Management Unit (MMU) that enables various functionality of the virtual memory subsystem.

Fig 4: Page Fault Handler
A higher level working of the page fault handler can be seen above. The translation look-aside buffer (TLB) is a fast hash table made use of by the CPU when trying to translate the virtual address to its corresponding physical address. A hit in the TLB is magnitudes faster than an access to the process’s page table in main memory. Only, when there is a miss does the CPU call into the kernel to handle the fault. The kernel then invokes the MMU to handle the fault. Once the fault is taken care of, the kernel interrupts the CPU to continue execution of the earlier read/write.
Diving into the MMU, when a valid access is made to a memory area (different from accessing a non-mapped memory area), the MMU carries over the read/write if the physical page is present. If the physical page is not present, the MMU uses soft faults for the page fault handler to handle various virtual memory functionality like copy-on-write, swapping, anonymous mapping, file-backed mapping, lazy allocation etc. The above process is done in a way such that the faulting process is not aware of the steps being done by the MMU on its behalf - to service a read/write.
To implement the various virtual memory functionality, the MMU makes use of a set of flags that feel the same but are different and used by different components of the MMU. The VM_READ, VM_WRITE, VM_SHARED and the VM_EXEC flags of a memory mapping are used by the MMU to generate soft faults for the page fault handler to handle and the VM_MAYREAD, VM_MAYWRITE, VM_MAYSHARE and the VM_MAYEXEC flags are used by the page fault handler to verify if the actual read/write is valid and should be serviced.
Let us look at how each access propagates down to the MMU and the to the page fault handler and how they are serviced. For an access to an unmapped memory area, the MMU is invoked to handle the fault and it first checks to see if the mapping entries are present in the process’s page table. Since, this address falls in the unmapped region of the process, there will not be any Page Table Entries (PTEs) for this access. In this situation, the MMU will raise a signal (SIGSEVG) and the kernel will dump the cores, if configured.
If the access is for a valid mapping, the MMU is again invoked to check if there are Page Table Entries (PTE) for this mapping. Now assuming, this access has the data in memory (on a physical page), the MMU translates the virtual memory access to its corresponding physical address and does the read/write. Another situation is where an access is made for a valid mapping but whose corresponding data is not in memory (swapped out to disk, first access etc), the MMU raises a soft fault for the page fault handler to handle the above situation.
If the page fault handler determines that the access is valid, it works to modify the page table entries for the process to service the request. Also, this is done without the faulting process being aware of the operations taking place to service a read/write over the virtual memory subsystem
Let us now see how various virtual memory features are implemented, at a high level — by the MMU along with the page fault handler.
Lazy Allocation #
Using the virtual memory sub-system, Linux is able to delay the actual allocation until the physical page is needed to service the read/write. Linux wants to perform allocations only when needed - for performance and resource improvements.
We shall now look at how lazy allocation works with different types of mappings. The core idea behind all the types are the same regarding the lazy allocation and they differ in how the page fault handler maintains and responds to various situations.
Anonymous Mapping #
Programs allocate memory by creating anonymous mappings through mmap(). These are mappings that are not backed by any file. Consider the following system call:
add = mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE, -1, 0);
The above system call is used to create a private anonymous mapping, of length 4096, to be used by the calling program. When this request comes in, the kernel does the bare minimum to service this request. The virtual addresses for the mapping are created. No physical pages are allocated as of yet. The kernel then creates the Page Table Entries (PTE) for these virtual addresses. Each of the virtual address will have its VM_READ, VM_WRITE, VM_SHARED and VM_EXEC set to false (we shall see why this is the case). The VM_MAYREAD, VM_MAYWRITE, VM_MAYSHARE and the VM_MAYEXEC may however be set as appropriate. In our request, we have set the protection to be a combination of PROT_READ and PROT_WRITE. Hence, VM_MAYREAD and VM_MAYWRITE will be set to true.
No memory is allocated as of yet, except for the PTEs and no physical pages are allocated for the virtual addresses. This can be ensisioned below as:
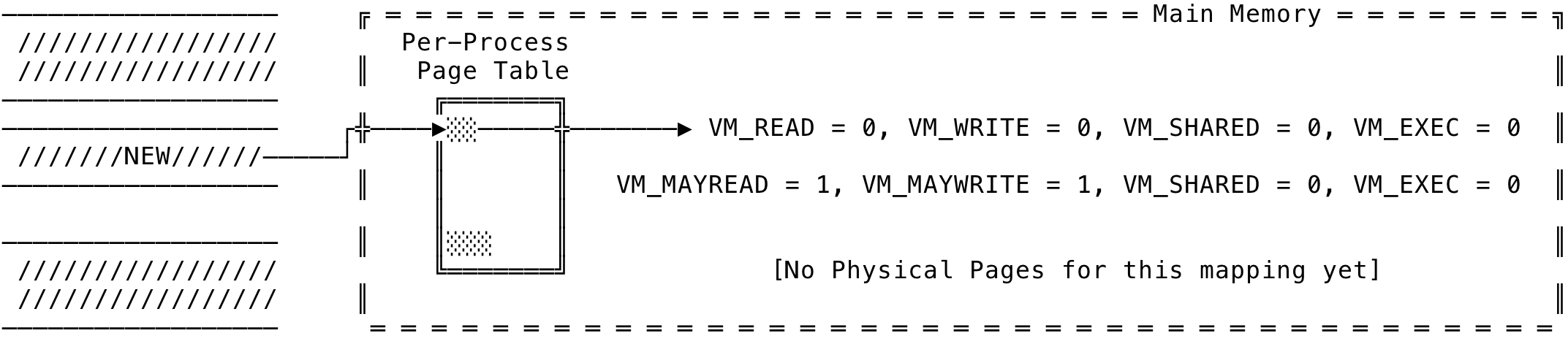
Fig 5: Anonymous Mapping - Create
Now, when the read/write comes in is where the majority of the work would be done by the kernel. Let us first look at what happens when a read comes in after a mapping is created. When the read comes into the MMU, it will check if there are Page Table Entries (PTE) for the requested virtual address. Since, the PTEs will be available the MMU will go ahead and check the permission bits. And, due to VM_READ being set to false, the MMU will raise a soft-fault for the page fault handler to handle this situation. Now, the page fault handler will come into the picture and check the VM_MAYREAD bit. And with this being set, the page fault handler knows that this is a valid operation. The page fault handler will get or create the zero page in physical memory — this one physical page will be shared across all processes in the system. The virtual addresses present, for this mapping, in the page table are modified. The virtual address are also marked as copy-on-write. This is flag is used to defer the work of actual allocation to when a write happens on the mapping. Once the page fault handler is done modifying the PTEs and the VM_READ bit set to true, the control is then passed to the MMU to proceed with translating the virtual address to its corresponding physical address. This is the reason you get 0 in the below code:
add = mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE, -1, 0);
printf("%d", *add);
Important to note here, the process is not aware of all the steps happening underneath it’s feet. Once the MMU completes the translation, the read happens - although it is a read to the zero page. The PTEs for the virtual addresses for this mapping will now contain the modified bits. This can be visualized as below:
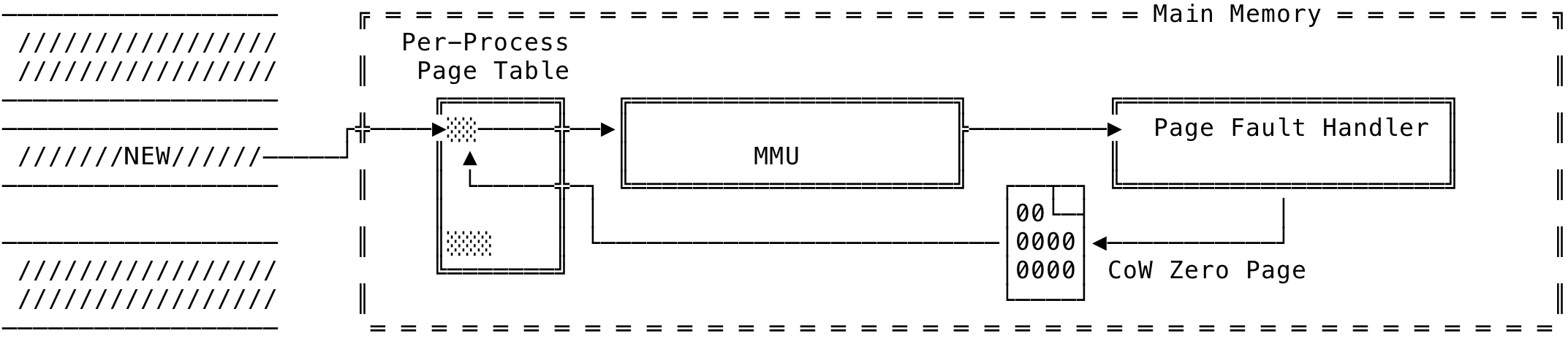
Fig 6: Anonymous Mapping - Read
The high level pseudo code would be like (pardon the relaxations):
def get_paddr_for_read(v_addr):
pte = page_table.get(v_addr, Nil)
if not pte:
raise SIGSEGV(some_info)
if not pte.permissions & VM_READ:
err = page_fault_handler(pte)
if err:
raise PermissionErr(err)
if not pfh.valid_access(pte):
raise PermissionErr(err)
zero_page = get_zero_page()
pfh.update_pte_with_COW(pte, zero_page)
p_addr = translate(v_addr)
return p_addr
Now, for a write on the virtual addresses of the mapping. To write to the virtual address, a read is first done for the virtual address provided and when the kernel does the write on the copy-on-write zero page, an another soft-fault is raised for the page fault handler to handle. Now, since we need to store the write on physical memory, a new physical page is allocated — which is the actual allocation, the PTEs modified and the physical address calculated. Once this is done, the translation is done by the MMU for the virtual address and the kernel goes ahead with the write. This can be visualized as below:
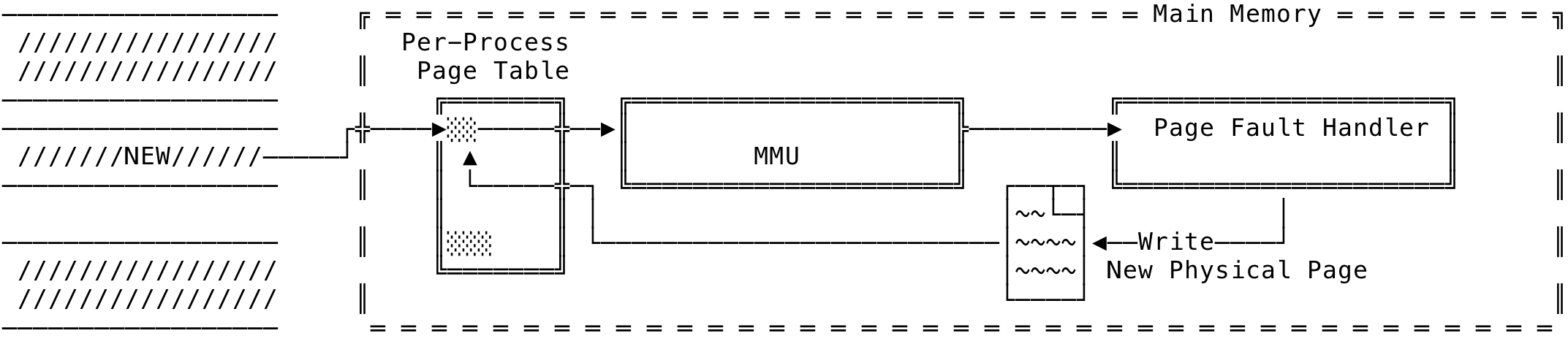
Fig 7: Anonymous Mapping - Write
The high level pseudo code would be like (pardon the relaxations):
def get_paddr_for_write(v_addr):
pte = page_table.get(v_addr, Nil)
if not pte:
raise SIGSEGV(some_info)
// ...
if pte.copy_on_write:
new_page = get_physical_page()
pfh.update_pte_with_new_page(pte, new_page)
p_addr = translate(v_addr)
return p_addr
The write will now happen on the physical address translated by the MMU. The new PTEs modified by the page fault handler and will now contain the right permissions for the virtual addresses of that mapping.
File Backed Mapping #
A file backed memory mapping is used to map a region of a file into the calling process’s memory mapping. The file can then be manipulated directly in memory as you would using virtual addresses — without the need for system calls. The kernel takes care of loading the desired pages in memory based on read/write to the region in the memory mapping.
Whether two process mapping the same regions of the file, can see each other’s edits - depends on the whether is mapping is private or shared.
Consider the following mmap() call:
add = mmap(NULL, file_size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
The above creates a shared mapping - which the process can read/write, for the entire file represented by fd. The mapping starts are offset 0. More details about mmap() can be found here.
As seen earlier with anonymous mapping, the above calls returns with the bare minimum work done by the kernel. The virtual addresses for the new mapping are created and these virtual addresses are added to the process’s page table. The flags VM_READ, VM_WRITE, VM_SHARED and VM_EXEC are set to false.
When a read comes in for the virtual addresses in the mapping, the MMU raises a soft-fault for the page fault handler. The page fault handler checks the permission bits (VM_MAY*), then gets the physical page from the page cache, increases the usage count by one, modifies the PTEs for the virtual address along with the new permissions. The control is then passed to the MMU which proceeds with the virtual to physical transformation. The page cache is maintained by the kernel to speed up disk read/write. The mappings, during a read, can make use of these pages without the need for a new physical page, since the page is faulted in by the page cache itself. This can be visualized as:

Fig 8: File Backed Mapping - Shared Read
When a write comes in for the virtual address in the mapping, the MMU again raises a soft-fault for the page fault handler. The page fault handler then writes to the physical page shared with the page cache and this results in a dirtied page. The PTEs for the virtual address is modified and the right permissions inserted by the page fault handler for us. And since the above mapping is shared, the changes are immediately visible to other process that have mapped the same exact file in the same region. Note, the write is not immediately written to disk and the write-back is taken care of by the kernel. This can be visualized as:

Fig 9: File Backed Mapping - Shared Write
The high level pseudo code would be like (pardon the relaxations):
def get_paddr_for_file_mapped_read(v_addr):
pte = page_table.get(v_addr, Nil)
if not pte:
raise SIGSEGV(some_info)
if not pte.permissions & VM_READ:
// ...
pfh.read_file(fd, off)
p_page = get_physical_page_from_page_cache()
pfh.update_pte_with_new_page(pte, new_page)
p_addr = translate(v_addr)
return p_addr
Let us now consider a private file backed memory mapping created by the following mmap() call:
add = mmap(NULL, file_size, PROT_READ|PROT_WRITE, MAP_PRIVATE, fd, 0);
We shall now see what happens when we read/write to the private memory mapping created above. The first read is the same as seen above for a shared file backed mapping seen above except that the page fault handler places a copy-on-write protection on the PTEs. This can be visualized as:

Fig 10: File Backed Mapping - Private Read
Now, when a write comes in, an actual allocation is done - wherein a physical page is allocated and the new data written to the newly allocated physical page. The page fault handler modifies the PTEs for the virtual address and the corresponding permissions changed. The usage count for the old page is decremented. The new page now differs from the kernel’s page cache copy. Note, for a shared read/write - no additional allocations are needed and the page cache’s physical copy can be used instead but a write on the file backed private memory mapping will involve additional allocations. This can be visualized as:

Fig 11: File Backed Mapping - Private Write
The high level pseudo code would be like (pardon the relaxations):
def get_paddr_for_read(v_addr):
pte = page_table.get(v_addr, Nil)
if not pte:
raise SIGSEGV(some_info)
if pte.copy_on_write:
// ...
decrement_usage_count(pte)
new_page = get_physical_page()
pfh.update_pte_with_new_page(pte, new_page)
p_addr = translate(v_addr)
return p_addr
Copy-On-Write #
Copy-on-Write is a technique used by the page fault handler to delay the physical page allocation only when it is actually needed. We had seen Copy-on-Write in action earlier where the read in an anonymous mapping/file backed private mapping resulted in a Copy-on-Write page being provided to us to work with.
In some situations, during a read, the new mapping can point to a shared mapping - either through a private file backed mapping or a child referencing a parent’s anonymous mapping. They only need to diverge when an edit is made. Hence the page fault handler will maintain a single physical page, protect it using Copy-on-Write (the read bit is enabled but a write is disabled) to let multiple process share the same physical page. The single physical page will have its usage count set as appropriate. Each of the page table entires will be Copy-on-Write protected. The shared bit is also set on the physical page.
When a write come into such a page, the page fault handler is invoked. It allocates a new physical page and copies over the data to it. It decrements the usage count of the earlier page and the PTEs for the access is updated with the new physical page. The write is now allowed to go to the new page. The new page is not shared since it is of a private mapping. This can be visualized something as:
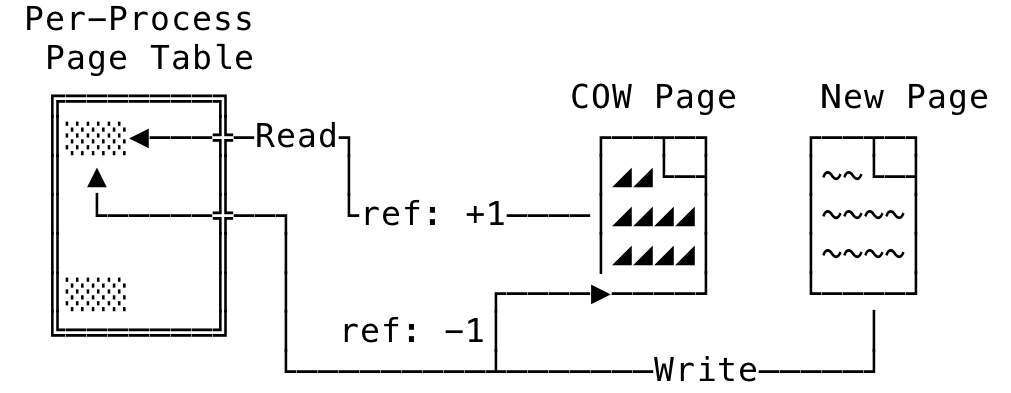
Fig 12: Copy-on-Write
Page Types #
We shall now look at the various types of pages used to provide virtual memory features by the virtual memory subsystem. We have already seen a few of then earlier and this will go into a bit more detail about each one of them.
Shared Pages #
Shared pages are used to share data between different processes. They can be used for Inter-Process Communications (IPC) among various others. Multiple process will map its virtual address’s PTE to the same shared physical page. Changes to these virtual addresses from multiple processes are visible to each other.
The kernel maintains a usage count for the physical page and when the count gets to 0, it can be effectively freed/re-used. Copy-on-Write protection is also provided by the page fault handler using shared pages as seen earlier.
The shared page can be created either through an anonymous mapping or a file backed mapping. For a file backed mapping, if multiple process maps to the same file and offset, the contents will be shared with all the process (Together with the page cache). Any changes to the mapping by any of the sharing process will be made visible to others sharing the mapping.
Consider the following code:
add = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
Here, a file backed shared memory mapping is created for file represented using fd. Other process which map the same file and offset can see/make changes to the file and every other mapping for the same regions would be kept in sync.
For a anonymous shared mapping, when the parent forks a child, the child and the parent share the mapping and changes made by the parent or the child can be seen by each other.
Consider the following code:
add = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, -1, 0);
*add = 42
...
pid = fork();
...
Here, the add represents a memory mapping that can be shared by the parent and child. The change done by the parent, assigning it to 42, will be visible to the child and vice-versa.
The workings for shared mappings can be visualized as something below:
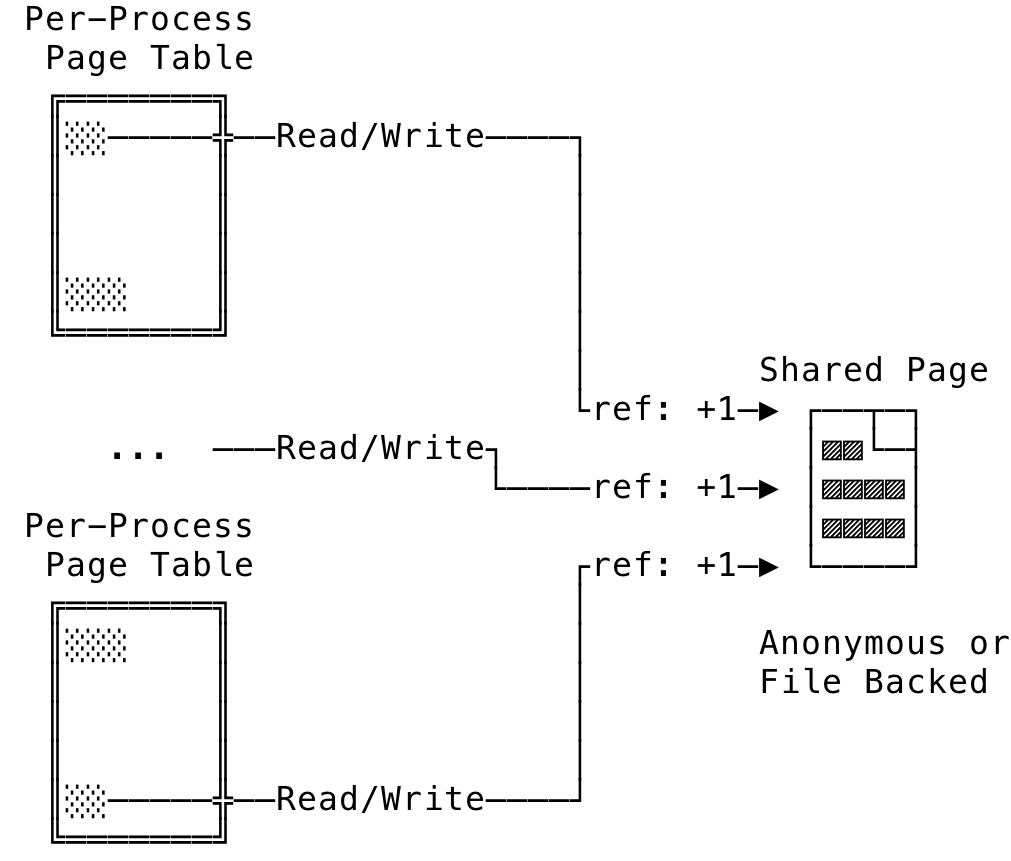
Fig 13: Shared Pages
Active/In-Active Pages #
The kernel maintains a list of active and in-active pages. When the physical space is low and space needs to be reclaimed, the kernel goes through the list of in-active pages and performs a write-back/swap on it. This page is then available for the requesting process to be used as memory mappings. When the swapped/written back data is needed again, a clean/free page is chosen and the data copied over to service the request.
This mechanics is to ensure that active pages are not reused (or only after exhausting other pages) since the data will be faulted into main memory very soon and the page fault handler needs to again perform extra work in this situation. The goal is to minimize such work by working with the not very active pages. This could be visualized as:
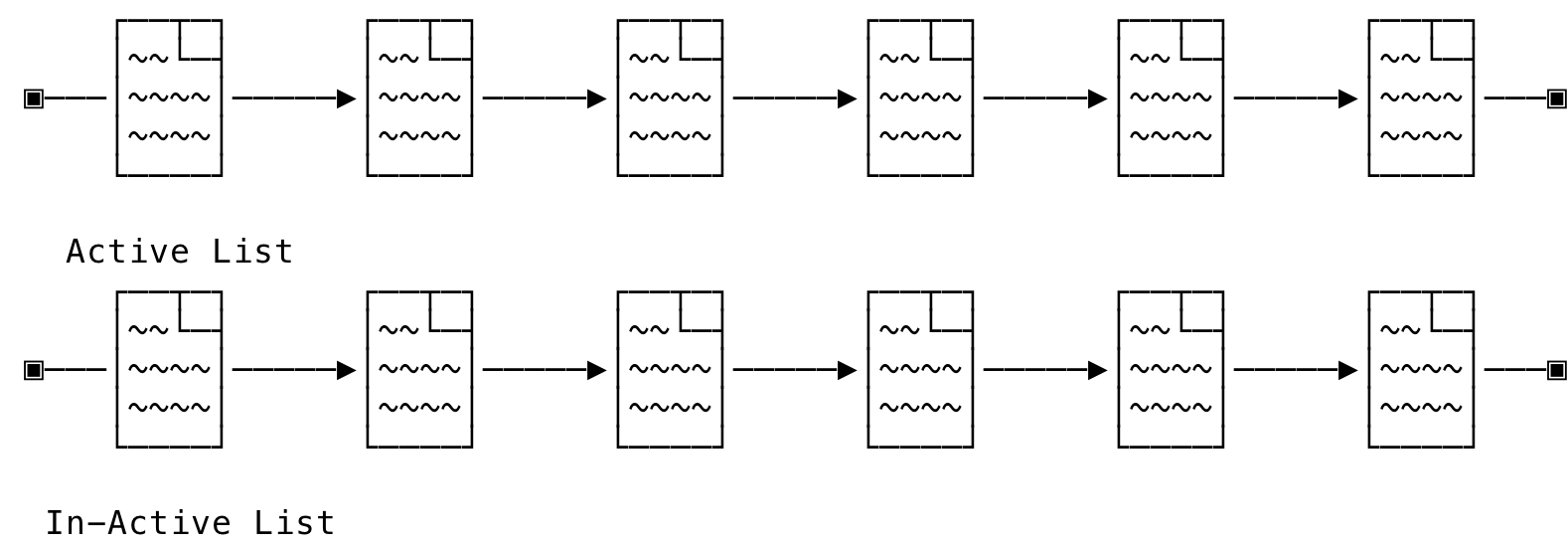
Fig 14: Active Pages List
The first access results in the page being added to the in-active list and further access moves it up to the active list. The kernel does extra work to balance both the list and make sure they are kept in some configurable ratio to each other. More information can be seen here.
Swapped Pages #
When physical space is low, private pages are written to a swap area — mostly disk and those pages are freed for any new allocations that might occur. The PTEs for that mapping are modified and scored against so that when the swapped out page is needed again, the page fault handler knows where to look for the swapped out page.
The kernel looks for triggers within the system to start swapping out pages to the swap area. The size of the swap area and the swapping devices can be configured as needed.
More information can be seen here.
Clean Pages #
Clean pages are pages that have their data stored in the file (for a file back mapping) or a swap (for an anonymous mapping). These pages can essentially be reclaimed and re-used when needed by other process.
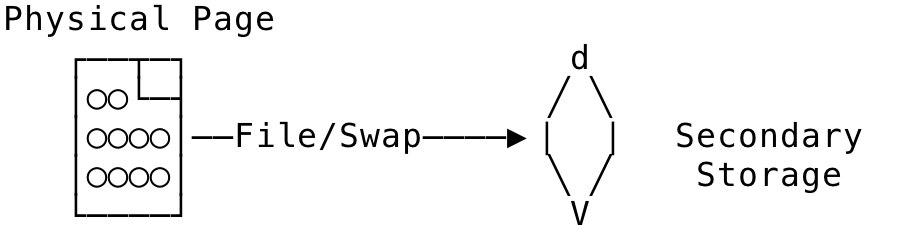
Fig 15: Clean Pages
Free Pages #
Free pages are pages that are in a free list and not used by any process. These pages are essentially waiting for any requests to come in for it to be used by a process or page cache.
Free pages get created when a process exits or calls munmap() to discard memory mappings. The free pages are usually used by the page cache to increase the disk read/write until they are actually needed. The kernel is responsible for finding uses for these pages to increase the speed of various operations within the system. You can see the free space in the system using the free command.
Thrashing #
During low physical memory situations, the page fault handler tries to satisfy each new physical allocation by swapping out the contents of an already existing physical page (to disk or to the backing file for example) and copying over the new contents to that physical page. Now, if that swapped out page was an active page - although the kernel tries to avoid this situation but low memory enables this, when the contents in the swap are again needed, another active page is then swapped out to bring in its contents and this goes on and on. The majority of the work in the system is now swapping out pages and re-using the active page, instead of servicing the actual request. This situation is called thrashing and this could lead to CPU raising page faults without having much to do and spending its time being idle waiting for the I/O to complete.
Let us see why this situation can occur. The working set of a process is the set of pages required to complete a particular operation. When the process gets to run on the CPU, the page fault handler makes sure that the process’s working set is in memory. In low memory situations, the page fault handler steals pages from an another process, writes out the contents to disk/backing file and re-uses the physical page for the current active process. So, during low memory situations, this gets accelerated and leads to a situation described above. This can be visualized as:
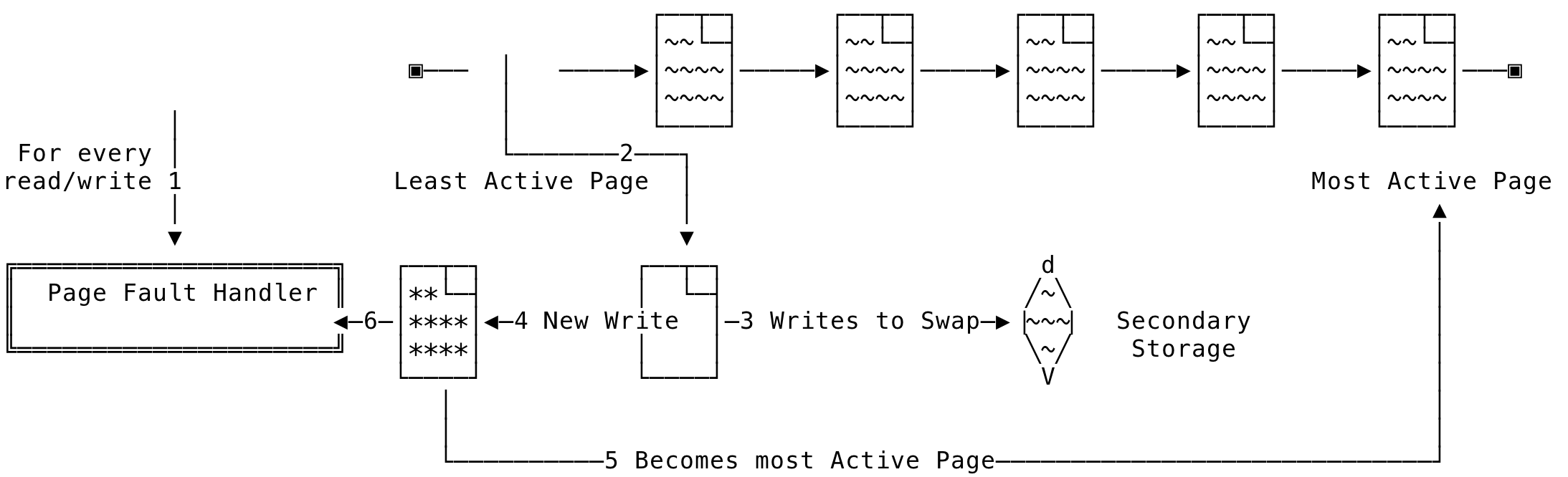
Fig 16: System Thrashing
If the system swap is too small, this gets filled up early and the page fault handler will steal file backed mappings. And since every executable and shared code is a filed backed mapping, those pages are used and this further accelerates the situation since they will be faulted very soon by other processes. The kernel’s OOM Killer will be invoked in these situations to kill processes and make the system stable again.
That’s it. Hope this post provided a clear picture on how the virtual memory subsystem works on Linux. We also saw how it enables various functionalities like lazy allocation, copy-on-write, file backed mappings etc. For any discussion, tweet here.
[1] https://landley.net/writing/memory-faq.txt - One of the best written article that describes Linux’s virtual memory. Short and wonderful.